本文已超過一年。較舊的文章可能包含過時的內容。請檢查頁面中的資訊自發布以來是否已變得不正確。
使用 Kubernetes 和 TensorFlow Serving 擴展神經網路影像分類
在 2011 年,Google 開發了一個名為 DistBelief 的內部深度學習基礎架構,讓 Google 員工能夠建構更大的神經網路,並將訓練擴展到數千個核心。去年年底,Google 推出了 TensorFlow,其第二代機器學習系統。TensorFlow 通用、靈活、可移植、易於使用,最重要的是,它是與開放原始碼社群共同開發的。

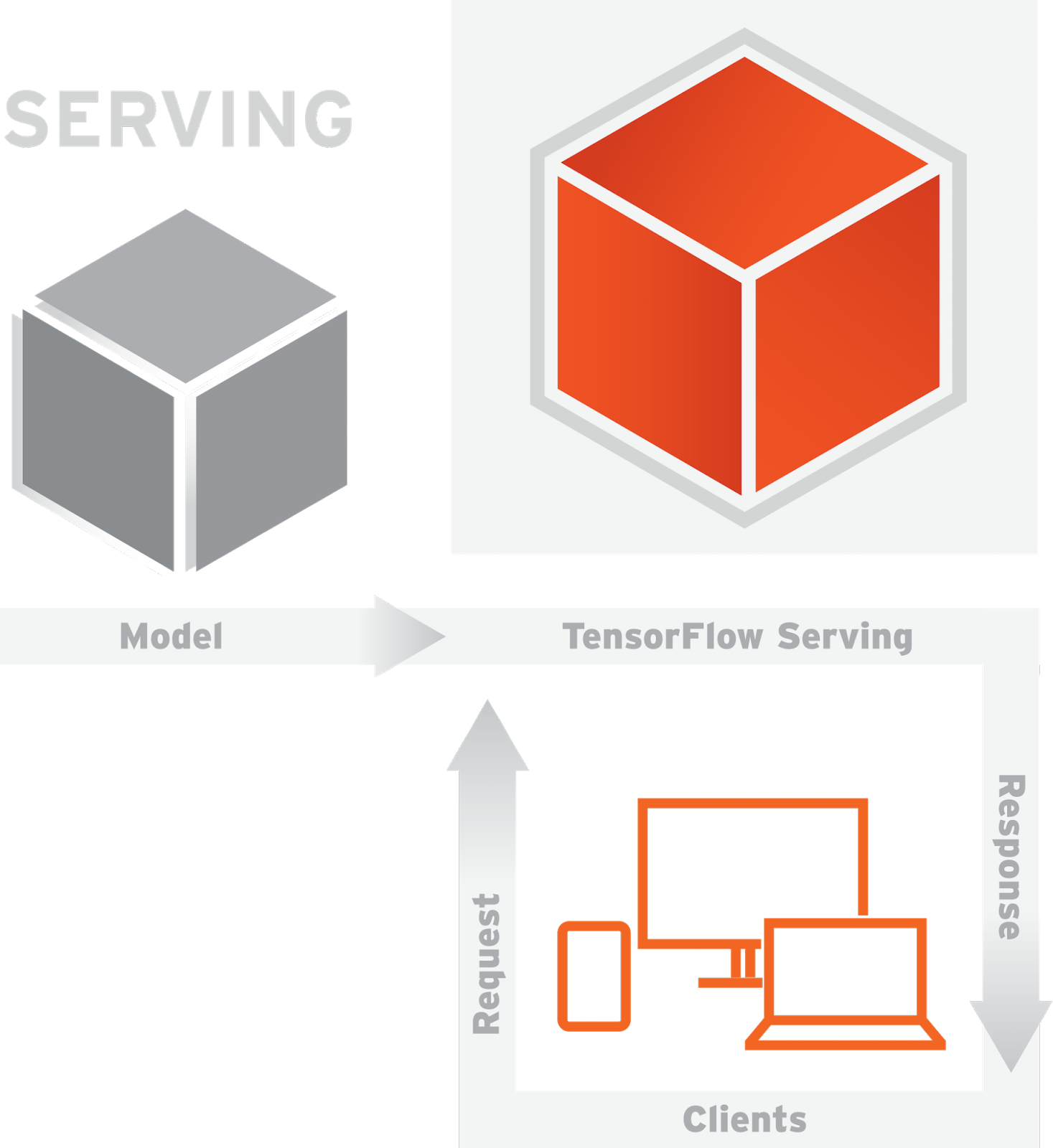
將機器學習導入產品的流程包括在您的資料集上建立和訓練模型,然後將模型推送至生產環境以服務請求。在這篇部落格文章中,我們將向您展示如何將 Kubernetes 與 TensorFlow Serving(一個高效能、開放原始碼的機器學習模型服務系統)結合使用,以滿足您應用程式的擴展需求。
讓我們以影像分類作為一個範例。假設您的應用程式需要能夠在一組類別中正確識別影像。例如,給定下方可愛的小狗影像,您的系統應將其分類為拉布拉多犬。
|  | | 圖片來源:維基百科 |
| | 圖片來源:維基百科 |
{kind=link}
您可以使用 TensorFlow 和在 ImageNet 資料集的資料上訓練的 Inception-v3 模型來實作影像分類。此資料集包含影像及其標籤,這讓 TensorFlow 學習器能夠訓練一個模型,供您的應用程式在生產環境中使用。
 一旦模型經過訓練並匯出,TensorFlow Serving 就會使用該模型執行推論 — 根據其用戶端提供的全新資料進行預測。在我們的範例中,用戶端透過 gRPC(Google 的高效能、開放原始碼 RPC 框架)提交影像分類請求。
一旦模型經過訓練並匯出,TensorFlow Serving 就會使用該模型執行推論 — 根據其用戶端提供的全新資料進行預測。在我們的範例中,用戶端透過 gRPC(Google 的高效能、開放原始碼 RPC 框架)提交影像分類請求。
推論可能非常耗費資源。我們的伺服器會執行以下 TensorFlow 圖形來處理其接收的每個分類請求。Inception-v3 模型具有超過 2700 萬個參數,每次推論執行 57 億次浮點運算。
|  | | Inception-v3 的示意圖 |
| | Inception-v3 的示意圖 |
幸運的是,這正是 Kubernetes 可以幫助我們的地方。Kubernetes 使用其外部負載平衡器在叢集中分配推論請求處理。叢集中的每個 Pod 都包含一個 TensorFlow Serving Docker 映像檔,其中包含基於 TensorFlow Serving 的 gRPC 伺服器和經過訓練的 Inception-v3 模型。該模型表示為一組檔案,描述 TensorFlow 圖形的形狀、模型權重、資產等等。由於所有內容都整齊地打包在一起,我們可以動態擴展複製 Pod 的數量,使用 Kubernetes Replication Controller 以跟上服務需求。
為了幫助您親自試用,我們編寫了一個逐步教學,向您展示如何建立 TensorFlow Serving Docker 容器以服務 Inception-v3 影像分類模型、配置 Kubernetes 叢集並對其執行分類請求。我們希望這能讓您更輕鬆地將機器學習整合到您自己的應用程式中,並使用 Kubernetes 進行擴展!若要進一步了解 TensorFlow Serving,請查看 tensorflow.github.io/serving。