本文已超過一年。較舊的文章可能包含過時的內容。請檢查頁面中的資訊自發布以來是否已變得不正確。
資源管理工作小組介紹
我們為何在此?
Kubernetes 已發展為支援多樣化且日益複雜的應用程式類別。我們可以將基於微服務、批次工作和具有持久儲存需求的有狀態應用程式的現代雲原生 Web 應用程式加入並擴展。
然而,Kubernetes 仍有改進的機會;例如,執行需要專門硬體的工作負載的能力,或是在考量硬體拓撲時效能顯著提升的工作負載。這些衝突可能會使應用程式類別(尤其是在已建立的垂直產業中)難以採用 Kubernetes。
我們在此看到前所未有的機會,若錯失機會將付出高昂的代價。Kubernetes 生態系統必須創造一條可消耗的路徑,以有意義的方式滿足尚未服務的工作負載需求,從而邁向下個世代的系統架構。「資源管理工作小組」以及其他 SIG 必須展現客戶想看到的願景,同時讓解決方案能夠在完全整合、經過周詳計畫的端對端堆疊中良好運行。
當特定挑戰需要跨 SIG 協作時,就會建立 Kubernetes 工作小組。「資源管理工作小組」例如主要與 sig-node 和 sig-scheduling 合作,以推動 Kubernetes 中額外的資源管理功能支援。我們確保經常諮詢來自各個 SIG 的主要貢獻者,因為工作小組並非旨在代表任何 SIG 做出系統級決策。
其中一個範例和主要好處是工作小組與 sig-node 的關係。我們能夠在考慮頂層功能設計之前,確保完成多個版本的節點可靠性工作(在 1.6 版中完成)。這些設計是以使用案例驅動的:研究各種工作負載的技術需求,然後根據對最大橫斷面的可衡量影響進行排序。
目標工作負載和使用案例
工作小組的主要設計原則之一是,使用者體驗必須保持簡潔和可攜性,同時仍能呈現企業和應用程式所需的基礎架構功能。
雖然不代表任何承諾,但我們希望在不久的將來,Kubernetes 能夠最佳化運行金融服務工作負載、機器學習/訓練、網格排程器、Map-Reduce、動畫工作負載等等。作為一個使用案例驅動的小組,我們考慮潛在的應用程式整合,這也有助於互補的獨立軟體供應商生態系統在 Kubernetes 之上蓬勃發展。
為何要這樣做?
Kubernetes 非常擅長涵蓋通用 Web 託管功能,那麼為何還要費力擴展 Kubernetes 的工作負載涵蓋範圍?事實是,今天 Kubernetes 優雅涵蓋的工作負載僅佔全球運算使用量的一小部分。我們有巨大的機會安全且有條不紊地擴展可以在 Kubernetes 上最佳化運行的工作負載集合。
迄今為止,在擴展工作負載涵蓋範圍的領域中已取得顯著進展
- 有狀態應用程式,例如 Zookeeper、etcd、MySQL、Cassandra、ElasticSearch
- 工作,例如處理當日日誌或任何其他批次處理的定時事件
- 透過 Alpha GPU 支援進行機器學習和運算綁定工作負載加速。總體而言,從致力於 Kubernetes 的人們那裡聽到客戶表示我們需要更進一步。繼 2014 年容器的巨大普及之後,業界言論圍繞著更現代、基於容器的資料中心級工作負載協調器,因為人們希望規劃他們的下一個架構。
因此,我們開始提倡擴大 Kubernetes 涵蓋的工作負載範圍,從整體概念到特定功能。我們的目標是將控制權和選擇權交到使用者手中,幫助他們充滿信心地朝著他們選擇的任何基礎架構策略邁進。在這種倡導中,我們很快找到了一大群志同道合的公司,他們對擴展 Kubernetes 可以協調的工作負載類型感興趣。因此,工作小組應運而生。
資源管理工作小組的起源
在 討論 在 CloudNativeCon | KubeCon Seattle 之後的 Kubernetes 開發者峰會 2016 期間進行了廣泛的開發/功能,我們決定 正式成立 我們鬆散組織的小組。2017 年 1 月,Kubernetes 資源管理工作小組 成立。該小組(由 Red Hat 的 Derek Carr 和 Google 的 Vishnu Kannan 領導)最初被視為一項臨時倡議,旨在向 sig-node 和 sig-scheduling(主要是)提供指導。然而,由於工作小組內目標的跨領域性質,以及快速揭露的 路線圖 深度,「資源管理工作小組」在最初的幾個月內成為其自身的實體。
最近,Google 的 Brian Grant (@bgrant0607) 在他的 Twitter 訊息 上發布了以下圖片。此圖片有助於解釋每個 SIG 的角色,並顯示「資源管理工作小組」在整體專案組織中的位置。
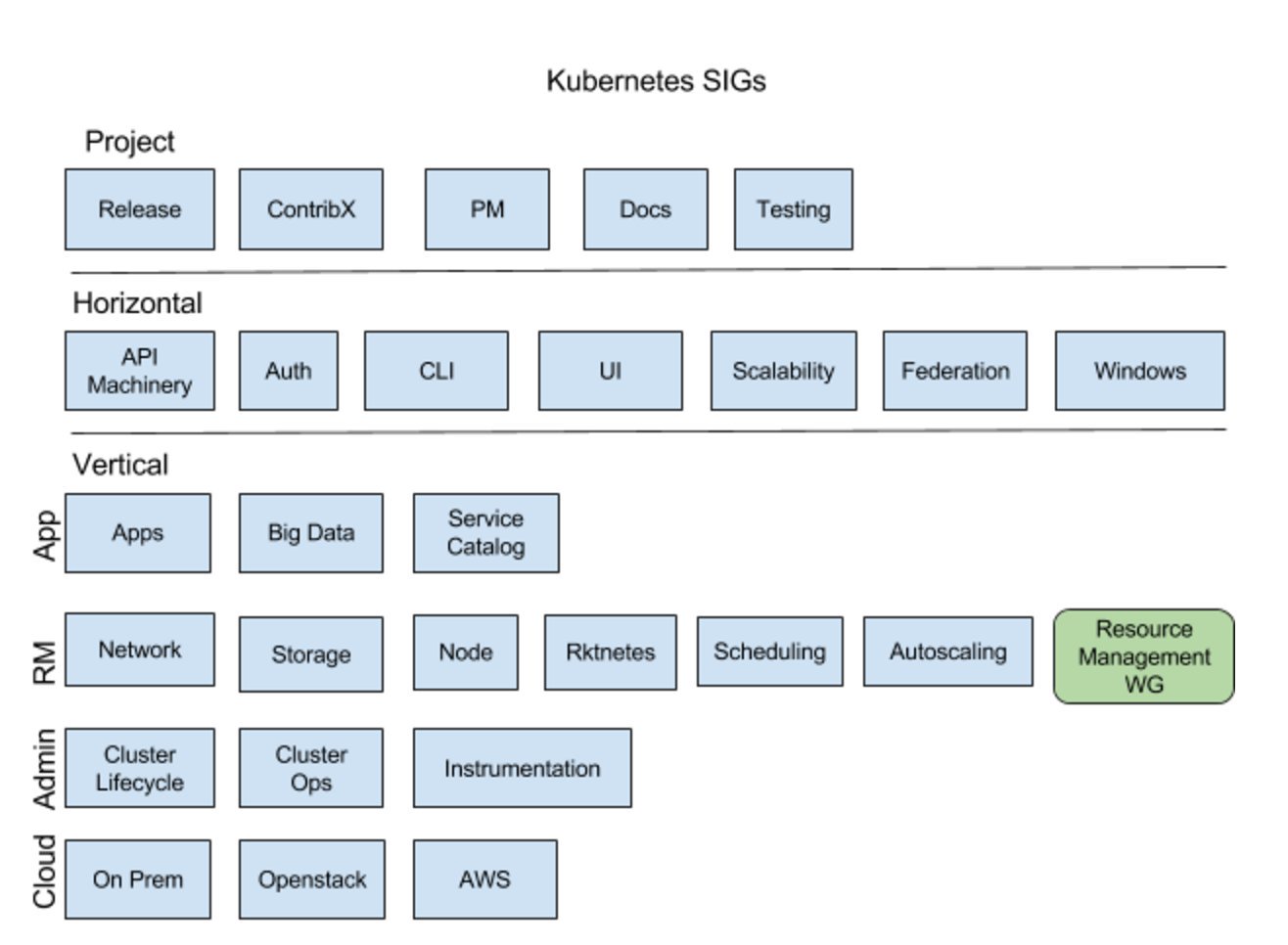
為了幫助啟動這項工作,「資源管理工作小組」於 2017 年 5 月舉行了首次面對面啟動會議。感謝 Google 的贊助!

來自 Intel、NVIDIA、Google、IBM、Red Hat 和 Microsoft(等等)的人員參與了會議。
您可以在 此處 閱讀為期 3 天的會議成果。
該小組在「資源管理工作小組」的 章程 中列舉的、用於增加 Kubernetes 工作負載涵蓋範圍的優先功能列表包括
- 支援效能敏感型工作負載(獨佔核心、CPU pinning 策略、NUMA)
- 整合新的硬體裝置(GPU、FPGA、InfiniBand 等)
- 改進資源隔離(本地儲存、HugePages、快取等)
- 改進服務品質(效能 SLO)
- 效能基準測試
- 與上述功能相關的 API 和擴充功能。討論清楚表明,各種工作負載的需求之間存在巨大的重疊,我們應該消除重複的需求,並以通用方式規劃。
工作負載特性
最初目標使用案例集具有以下一個或多個特性
- 確定性效能(解決長尾延遲)
- 單一節點內以及共用控制平面的節點群組內的隔離
- 對進階硬體和/或軟體功能的要求
- 可預測、可重現的放置:應用程式需要圍繞放置的精細保證。「資源管理工作小組」正在引領功能設計和開發,以支援這些工作負載需求。我們的目標是為這些情境提供最佳實務和模式。
初始範圍
在最近的面對面會議之前的幾個月中,我們討論了如何以保留可攜性和簡潔使用者體驗的方式安全地抽象資源,同時仍滿足應用程式需求。工作小組提出了一份多版本 路線圖,其中包括 4 個短期至中期目標,這些目標在目標工作負載之間具有很大的重疊
- Kubernetes 應提供對硬體裝置的存取,例如 NIC、GPU、FPGA、InfiniBand 等。
- Kubernetes 應提供一種方法,讓使用者透過「保證 QoS 層級」請求靜態 CPU 指派。在此階段不支援 NUMA。
- Kubernetes 應提供一種方法,讓使用者可以使用任何大小的巨頁。
- Kubernetes 應實作一個抽象層(類似於 StorageClasses),用於 CPU 和記憶體以外的裝置,允許使用者以可攜式方式使用資源。例如,Pod 如何請求具有最小記憶體容量的 GPU?
參與及摘要
我們的章程文件包含 聯絡我們 章節,其中包含指向我們的郵件列表、Slack 頻道和 Zoom 會議的連結。先前會議的錄音已上傳到 YouTube。我們計畫在奧斯丁的 CloudNativeCon | KubeCon 2017 Kubernetes 開發者峰會上討論這些主題和更多內容。請加入我們的其中一個會議(歡迎使用者、客戶、軟體和硬體供應商),並為工作小組做出貢獻!