本文已超過一年。較舊的文章可能包含過時的內容。請檢查頁面中的資訊自發布以來是否已變得不正確。
走出雲端,落地生根:如何在任何地方打造生產級 Kubernetes
本博客提供在內部部署資料中心或邊緣位置等環境中,運行生產級 Kubernetes 集群的一些指南。
「生產級」是什麼意思?
- 安裝是安全的
- 部署是透過可重複且記錄的流程進行管理
- 效能是可預測且一致的
- 更新和配置變更可以安全地應用
- 日誌記錄和監控已到位,以偵測和診斷故障和資源短缺
- 考量到可用資源,包括資金、物理空間、電力等限制,服務「具有足夠高的可用性」。
- 復原流程是可用的、有文件記錄的,並且經過測試,可在發生故障時使用
簡而言之,生產級意味著預期意外並準備復原,以盡可能減少痛苦和延遲。
本文針對在 Hypervisor 或裸機平台上,內部部署的 Kubernetes 部署,這些部署與主要公有雲的可擴展性相比,面臨有限的後端資源。然而,如果預算限制了您選擇消耗的資源,其中一些建議在公有雲中也可能有用。
單節點裸機 Minikube 部署可能便宜又容易,但不是生產級。反之,您不太可能在零售店、分公司或邊緣位置實現 Google 的 Borg 體驗,您也不太可能需要它。
本博客提供關於實現生產級 Kubernetes 部署的一些指導,即使在處理一些資源限制時也是如此。

Kubernetes 集群中的關鍵組件
在我們深入探討細節之前,了解 Kubernetes 的整體架構至關重要。
Kubernetes 集群是一個高度分散式的系統,基於控制平面和集群工作節點架構,如下圖所示。
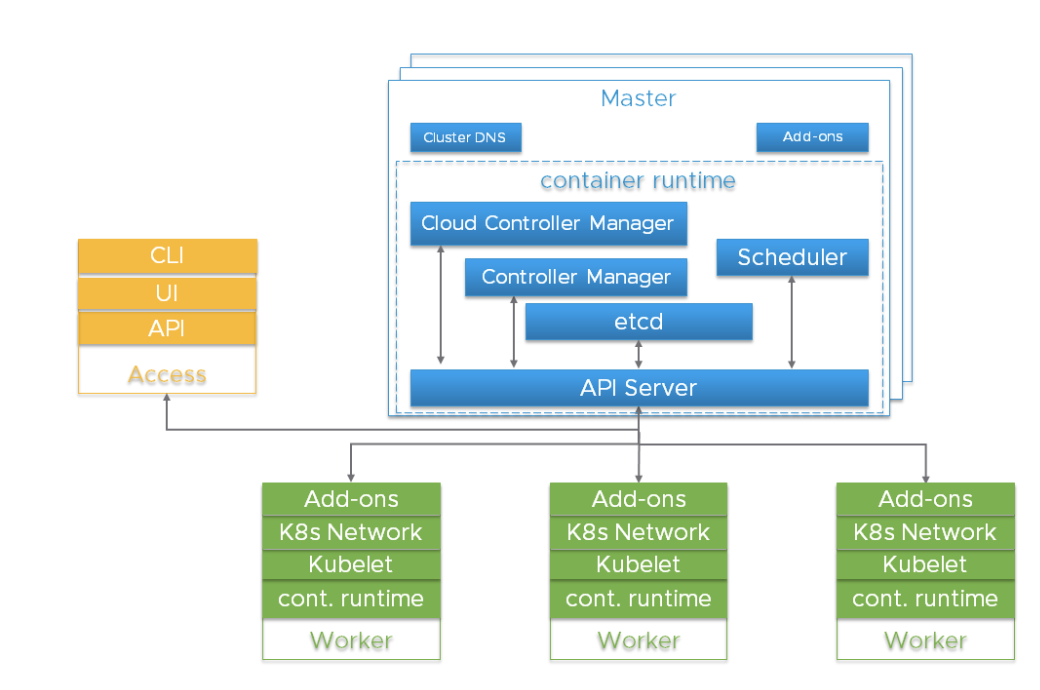
通常,API 伺服器、控制器管理器和調度器組件共同位於控制平面(又名 Master)節點的多個實例中。Master 節點通常也包含 etcd,儘管在高可用性和大型集群場景中,需要將 etcd 運行在獨立主機上。這些組件可以作為容器運行,並且可以選擇由 Kubernetes 監管,即作為靜態 Pod 運行。
為了實現高可用性,使用了這些組件的冗餘實例。重要性和所需的冗餘程度各不相同。
從 HA 角度來看 Kubernetes 組件
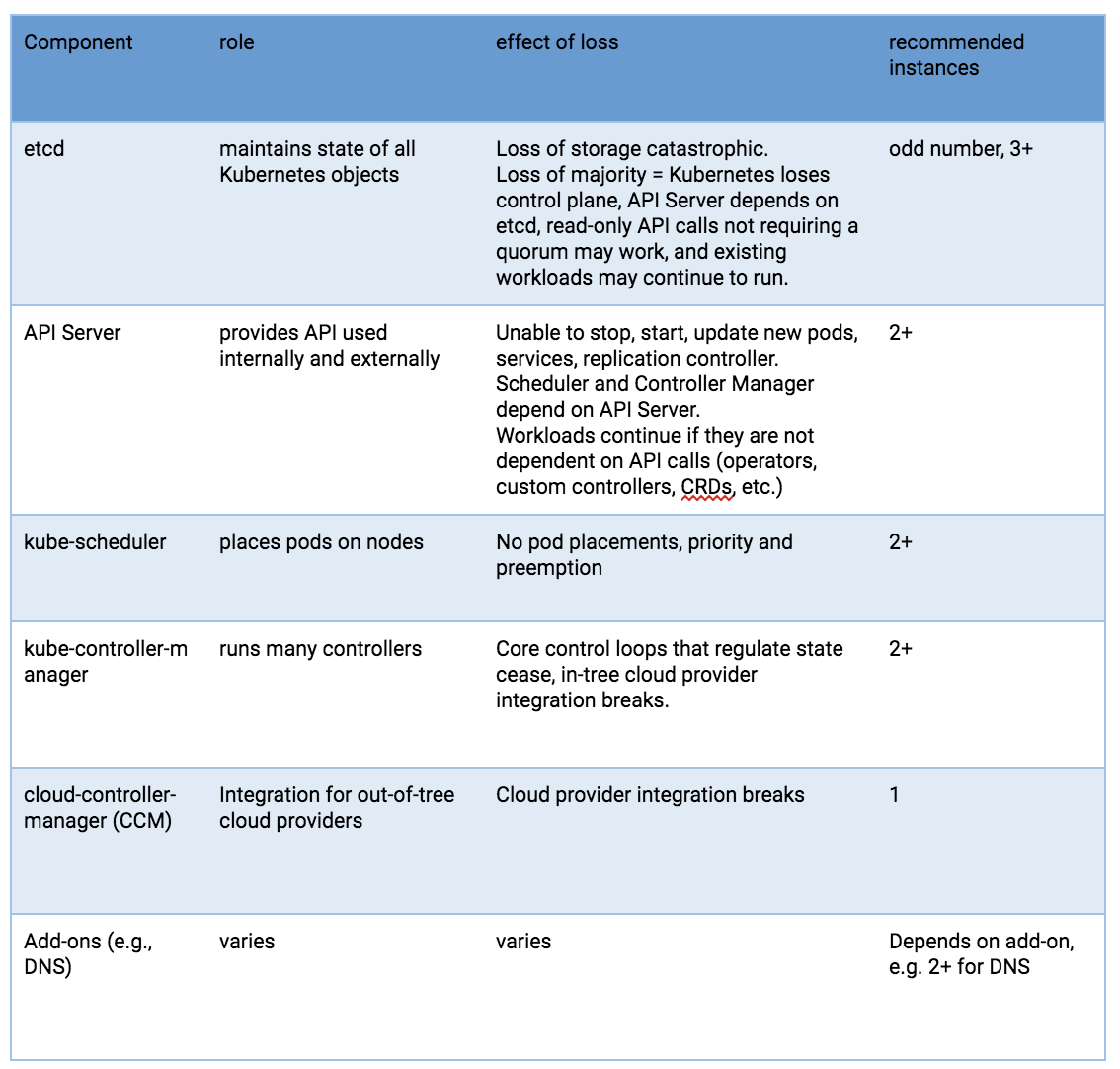
這些組件的風險包括硬體故障、軟體錯誤、錯誤的更新、人為錯誤、網路中斷以及導致資源耗盡的系統過載。冗餘可以減輕許多這些危害的影響。此外,Hypervisor 平台的資源調度和高可用性功能,對於超越僅使用 Linux 作業系統、Kubernetes 和容器運行時所能實現的功能非常有用。
API 伺服器在負載平衡器後使用多個實例,以實現規模和可用性。負載平衡器是實現高可用性的關鍵組件。如果您沒有負載平衡器,多個 DNS API 伺服器 ‘A’ 記錄可能是一種替代方案。
kube-scheduler 和 kube-controller-manager 參與領導者選舉過程,而不是使用負載平衡器。由於 cloud-controller-manager 用於選定類型的託管基礎設施,並且這些基礎設施具有實作差異,因此除了表明它們是控制平面組件之外,將不再討論它們。
在 Kubernetes 工作節點上運行的 Pod 由 kubelet 代理程式管理。每個工作節點實例都運行 kubelet 代理程式和 CRI 相容 的容器運行時。Kubernetes 本身旨在監控和從工作節點中斷中恢復。但是對於關鍵工作負載,可以使用 Hypervisor 資源管理、工作負載隔離和可用性功能來增強可用性並使效能更可預測。
etcd
etcd 是所有 Kubernetes 物件的持久性儲存。etcd 集群的可用性和可恢復性應是生產級 Kubernetes 部署的首要考量。
如果您負擔得起,五節點 etcd 集群是最佳實務。為什麼?因為您可以對其中一個進行維護,並且仍然可以容忍故障。即使只有單一 Hypervisor 主機可用,三節點集群也是生產級服務的最低建議。除非是跨越多個可用性區域的非常大型的安裝,否則不建議超過七個節點。
託管 etcd 集群節點的最低建議是 2GB RAM 和 8GB SSD 支援的磁碟。通常,8GB RAM 和 20GB 磁碟就足夠了。磁碟效能會影響故障節點的復原時間。有關更多資訊,請參閱 https://coreos.com/etcd/docs/latest/op-guide/hardware.html。
在特殊情況下考慮多個 etcd 集群
對於非常大型的 Kubernetes 集群,請考慮為 Kubernetes 事件使用單獨的 etcd 集群,以便事件風暴不會影響主要的 Kubernetes API 服務。如果您使用 flannel 網路,它會在 etcd 中保留配置,並且可能具有與 Kubernetes 不同的版本要求,這可能會使 etcd 備份變得複雜 - 請考慮為 flannel 使用專用的 etcd 集群。
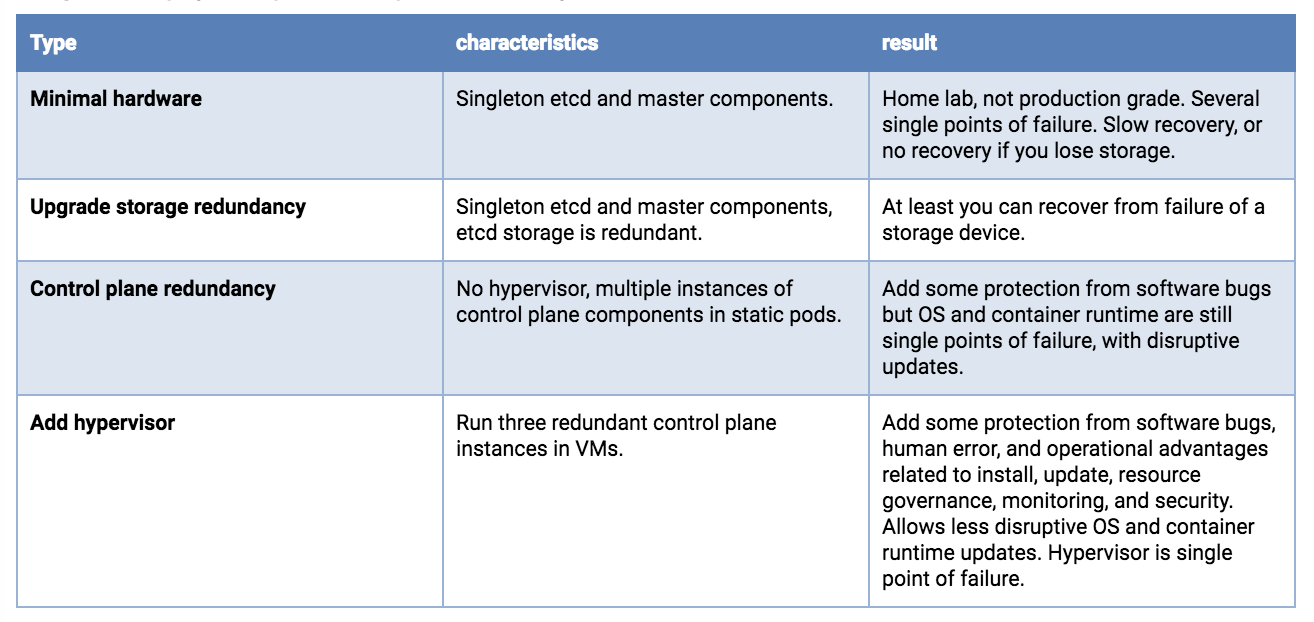
單主機部署
可用性風險列表包括硬體、軟體和人員。如果您僅限於單一主機,則使用冗餘儲存、錯誤校正記憶體和雙電源供應器可以減少硬體故障風險。在物理主機上運行 Hypervisor 將允許冗餘軟體組件的運行,並增加與部署、升級和資源消耗治理相關的操作優勢,在壓力下具有可預測和可重複的效能。例如,即使您只能負擔運行 Master 服務的單例,也需要保護它們免受過載和資源耗盡的影響,同時與您的應用程式工作負載競爭。與配置 Linux 調度器優先順序、cgroups、Kubernetes 標誌等相比,Hypervisor 可以更有效且更易於管理。
如果主機上的資源允許,您可以部署三個 etcd VM。每個 etcd VM 都應由不同的物理儲存設備支援,或者它們應使用使用冗餘(鏡像、RAID 等)的後端儲存的單獨分區。
如果您的單一主機有資源,則 API 伺服器、調度器和控制器管理器的雙冗餘實例將是下一個升級。
單主機部署選項,從最不適合生產到更好
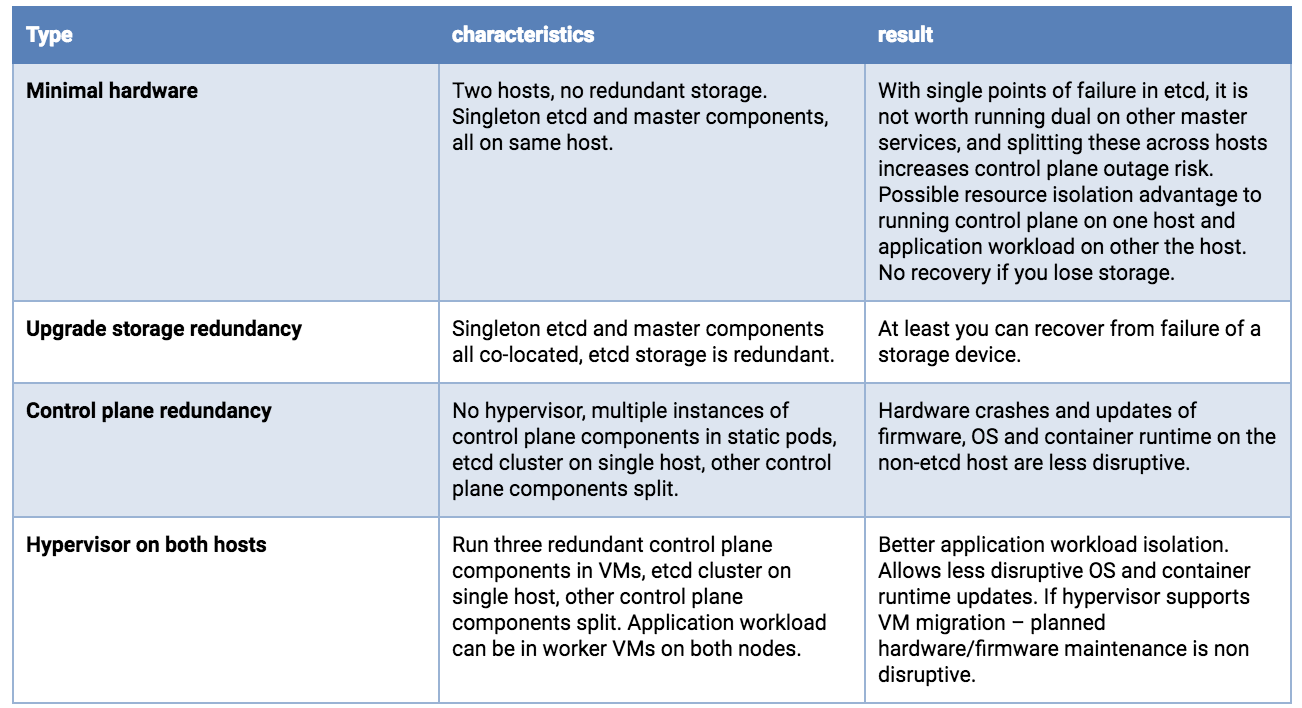
雙主機部署
使用兩台主機時,etcd 的儲存考量與單一主機相同,您需要冗餘。並且您最好運行 3 個 etcd 實例。雖然可能違反直覺,但最好將所有 etcd 節點集中在單一主機上。透過在兩台主機上進行 2+1 分割,您不會獲得可靠性 - 因為無論多數是 2 還是 3,持有大多數 etcd 實例的節點丟失都會導致中斷。如果主機不相同,請將整個 etcd 集群放在最可靠的主機上。
建議運行冗餘的 API 伺服器、kube-scheduler 和 kube-controller-manager。這些應跨主機分割,以最大程度地減少因容器運行時、作業系統和硬體故障而造成的風險。
在物理主機上運行 Hypervisor 層將允許冗餘軟體組件的運行,並具有資源消耗治理,並且可以具有計劃性維護操作優勢。
雙主機部署選項,從最不適合生產到更好
三(或更多)主機部署 - 邁向毫不妥協的生產級服務 建議在三台主機上分割 etcd。單一硬體故障將降低應用程式工作負載容量,但不應導致完全服務中斷。
對於非常大的集群,將需要更多 etcd 實例。
運行 Hypervisor 層提供操作優勢和更好的工作負載隔離。這超出了本文的範圍,但在三個或更多主機層級,可能會提供進階功能(集群冗餘共享儲存、具有動態負載平衡的資源治理、具有即時遷移或故障轉移的自動化健康監控)。
三(或更多)主機選項,從最不適合生產到更好

Kubernetes 配置設定
Master 和 Worker 節點應受到保護,免於過載和資源耗盡。Hypervisor 功能可用於隔離關鍵組件和保留資源。還有 Kubernetes 配置設定可以限制 API 呼叫率和每個節點的 Pod 數量等。某些安裝套件和商業發行版會處理此問題,但如果您正在執行自訂 Kubernetes 部署,您可能會發現預設值不合適,特別是如果您的資源很小或集群很大。
控制平面的資源消耗將與 Pod 數量和 Pod 變動率相關。非常大和非常小的集群將受益於 kube-apiserver 請求節流和記憶體的非預設設定。將這些設定得太高可能會導致請求超出限制和記憶體不足錯誤。
在工作節點上,應根據每個節點合理的支援工作負載密度配置 Node Allocatable。可以建立命名空間,以將工作節點集群細分為具有資源 CPU 和記憶體配額的多個虛擬集群。可以配置 Kubelet 處理 資源不足 條件。
安全性
每個 Kubernetes 集群都有一個集群根憑證授權機構 (CA)。需要產生和安裝控制器管理器、API 伺服器、調度器、kubelet 客戶端、kube-proxy 和管理員憑證。如果您使用安裝工具或發行版,這可能會為您處理。<此處描述了手動過程。您應該準備在節點更換或擴展時重新安裝憑證。
由於 Kubernetes 完全由 API 驅動,因此控制和限制誰可以訪問集群以及允許他們執行哪些操作至關重要。加密和身份驗證選項在此文檔中進行了說明。
Kubernetes 應用程式工作負載基於容器映像。您希望這些映像的來源和內容是可信任的。這幾乎總是意味著您將託管本地容器映像儲存庫。從公共互聯網提取映像可能會帶來可靠性和安全性問題。您應該選擇一個支援映像簽名、安全掃描、推送和提取映像的訪問控制以及活動記錄的儲存庫。
必須到位流程以支援應用於主機韌體、Hypervisor、作業系統、Kubernetes 和其他依賴項的更新。應到位版本監控以支援稽核。
建議
- 加強控制平面組件上的安全設定,使其超出預設值(例如,鎖定工作節點)
- 利用 Pod 安全策略
- 考慮您的網路解決方案可用的 NetworkPolicy 整合,包括您將如何完成追蹤、監控和故障排除。
- 使用 RBAC 來驅動授權決策和執行。
- 考慮物理安全,尤其是在部署到可能無人值守的邊緣或遠端辦公室位置時。包括儲存加密,以限制來自被盜設備的風險,並防止惡意設備(如 USB 密鑰)的連接。
- 保護 Kubernetes 純文字雲端提供商憑證(訪問金鑰、令牌、密碼等)
Kubernetes secret 物件適用於保存少量敏感資料。這些資料保留在 etcd 內。這些物件可以輕鬆用於保存 Kubernetes API 的憑證,但有時工作負載或集群本身的擴展需要功能更完整的解決方案。如果您需要的超出內建 secret 物件所能提供的範圍,HashiCorp Vault 專案是一個受歡迎的解決方案。
災難復原和備份

透過使用多個主機和 VM 來利用冗餘,有助於減少某些類別的中斷,但諸如全站自然災害、錯誤的更新、被駭客入侵、軟體錯誤或人為錯誤等情況仍可能導致中斷。
生產部署的關鍵部分是預期未來可能進行的復原。
還值得注意的是,如果您需要在多個站點進行大規模複製部署,那麼您在設計、記錄和自動化復原流程方面的一些投資也可能是可重複使用的。
DR 計劃的要素包括備份(以及可能的副本)、替換、計劃流程、可以執行該流程的人員以及定期培訓。可以使用定期測試演練和 混沌工程原則 來稽核您的準備情況。
您的可用性要求可能要求您保留作業系統、Kubernetes 組件和容器映像的本地副本,以便即使在互聯網中斷期間也能進行復原。「氣隙」場景中部署替換主機和節點的能力,也可以提供安全性和部署速度優勢。
所有 Kubernetes 物件都儲存在 etcd 上。定期備份 etcd 集群資料對於在災難情況下復原 Kubernetes 集群非常重要,例如遺失所有 Master 節點。
備份 etcd 集群可以使用 etcd 的 內建 快照機制來完成,並將產生的檔案複製到不同故障域中的儲存。快照檔案包含所有 Kubernetes 狀態和關鍵資訊。為了保護敏感的 Kubernetes 資料安全,請加密快照檔案。
使用基於磁碟區的 etcd 快照復原可能會出現問題;請參閱 #40027。基於 API 的備份解決方案(例如,Ark)可以提供比 etcd 快照更精細的復原,但也可能更慢。您可以同時使用快照和基於 API 的備份,但您至少應執行一種形式的 etcd 備份。
請注意,某些 Kubernetes 擴展可能會在獨立的 etcd 集群、持久性卷或透過其他機制中維護狀態。如果此狀態至關重要,則應制定備份和復原計劃。
某些關鍵狀態保存在 etcd 之外。憑證、容器映像以及其他與配置和操作相關的狀態,可能由您的自動化安裝/更新工具管理。即使可以重新產生這些項目,備份或複製也可能允許在故障後更快地復原。考慮為以下項目制定備份和復原計劃
- 憑證和金鑰對
- CA
- API 伺服器
- Apiserver-kubelet-client
- ServiceAccount 簽署
- “前端代理”
- 前端代理客戶端
- 關鍵 DNS 記錄
- IP/子網路分配和保留
- 外部負載平衡器
- kubeconfig 檔案
- LDAP 或其他身份驗證詳細資訊
- 雲端提供商特定的帳戶和配置資料
生產工作負載的考量
反親和性規範可用於在後端主機之間分割集群服務,但目前這些設定僅在排程 Pod 時使用。這表示 Kubernetes 可以重新啟動集群應用程式的故障節點,但在故障恢復後沒有原生機制重新平衡。這是一個值得單獨撰寫博客的主題,但補充邏輯可能對於在主機或工作節點復原或擴展後實現最佳工作負載放置很有用。Pod 優先順序和搶佔功能可用於在因故障或突增工作負載導致資源短缺時,指定首選的分類。
對於有狀態服務,外部附加卷掛載是非集群服務(例如,典型的 SQL 資料庫)的標準 Kubernetes 建議。目前,Kubernetes 管理的這些外部卷快照屬於 路線圖功能請求 的類別,可能與容器儲存介面 (CSI) 整合保持一致。因此,執行此類服務的備份將涉及特定於應用程式的 Pod 內活動,這超出了本文的範圍。在等待 Kubernetes 更好地支援快照和備份工作流程的同時,在 VM 而不是容器中運行資料庫服務,並將其暴露於您的 Kubernetes 工作負載可能值得考慮。
集群分散式有狀態服務(例如,Cassandra)可以受益於跨主機分割,如果資源允許,可以使用 本地持久性卷。這將需要部署多個 Kubernetes 工作節點(可以是 Hypervisor 主機上的 VM),以在單點故障下保持仲裁。
其他考量
日誌和 指標(如果收集並持久保留)對於診斷中斷很有價值,但鑑於可用技術的多樣性,本文將不作介紹。如果互聯網連線可用,則可能需要將日誌和指標外部保留在中央位置。
您的生產部署應使用自動化安裝、配置和更新工具(例如,Ansible、BOSH、Chef、Juju、kubeadm、Puppet 等)。手動流程將存在可重複性問題、勞動密集、容易出錯且難以擴展。認證發行版 很可能包含一個在更新過程中保留配置設定的功能,但如果您實作自己的安裝和配置工具鏈,則配置工件的保留、備份和復原至關重要。考慮將您的部署組件和設定保存在版本控制系統(例如 Git)下。
中斷復原
記錄復原程序的 Runbook 應經過測試並離線保存 - 甚至可以列印出來。當值班人員在星期五晚上凌晨 2 點被叫醒時,可能不是即興發揮的好時機。最好從預先計劃、經過測試的檢查清單中執行 - 遠端和現場人員可以共享訪問權限。
最後的想法

購買商業航空公司的機票既方便又安全。但是,當您前往跑道短的偏遠地區時,商業空中巴士 A320 航班並不是一個選項。這並不意味著航空旅行被排除在外。這確實意味著需要做出一些妥協。
航空業的格言是,在單引擎飛機上,引擎故障意味著您會墜毀。使用雙引擎,至少您可以有更多選擇墜毀地點。少量主機上的 Kubernetes 也是如此,如果您的商業案例證明是合理的,您可能會擴展到更大的大小車輛混合編隊(例如,FedEx、Amazon)。
那些設計生產級 Kubernetes 解決方案的人有很多選項和決策。一篇博客長度的文章無法提供所有答案,也無法了解您的具體優先事項。我們確實希望這能提供一份需要考慮事項的清單,以及一些有用的指導。某些選項被「擱置」(例如,使用自我託管而不是靜態 Pod 運行 Kubernetes 組件)。如果有人感興趣,這些可能會在後續文章中介紹。此外,Kubernetes 的高增強率意味著,如果您的搜尋引擎在 2019 年之後找到本文,則某些內容可能已過「有效期限」。