本文已超過一年。較舊的文章可能包含過時的內容。請檢查頁面中的資訊自發布以來是否已變得不正確。
KubeDirector:在 Kubernetes 上執行複雜的具狀態應用程式的簡易方法
KubeDirector 是一個開放原始碼專案,旨在讓在 Kubernetes 上執行複雜的具狀態橫向擴展應用程式叢集變得容易。KubeDirector 是使用自訂資源定義 (CRD) 框架建構的,並利用原生的 Kubernetes API 擴充功能和設計理念。這實現了與 Kubernetes 使用者/資源管理以及現有用戶端和工具的透明整合。
我們最近介紹了 KubeDirector 專案,這是我們稱為 BlueK8s 的更廣泛開放原始碼 Kubernetes 倡議的一部分。我很開心地宣布 KubeDirector 的 pre-alpha 程式碼現已推出。在這篇部落格文章中,我將展示它的運作方式。
KubeDirector 提供以下功能
- 在 Kubernetes 上執行非雲原生具狀態應用程式的能力,而無需修改程式碼。換句話說,沒有必要分解這些現有的應用程式以適應微服務設計模式。
- 原生支援保留應用程式特定的組態和狀態。
- 與應用程式無關的部署模式,最大限度地縮短將新的具狀態應用程式加入 Kubernetes 的時間。
KubeDirector 使熟悉資料密集型分散式應用程式 (如 Hadoop、Spark、Cassandra、TensorFlow、Caffe2 等) 的資料科學家能夠在 Kubernetes 上執行這些應用程式,只需極少的學習曲線,且無需編寫 GO 程式碼。由 KubeDirector 控制的應用程式由一些基本 metadata 和相關的組態 Artifacts 套件定義。應用程式 metadata 被稱為 KubeDirectorApp 資源。
若要了解 KubeDirector 的元件,請使用類似於以下的命令,在 GitHub 上複製儲存庫
git clone http://<userid>@github.com/bluek8s/kubedirector.
Spark 2.2.1 應用程式的 KubeDirectorApp 定義位於檔案 kubedirector/deploy/example_catalog/cr-app-spark221e2.json 中。
~> cat kubedirector/deploy/example_catalog/cr-app-spark221e2.json
{
"apiVersion": "kubedirector.bluedata.io/v1alpha1",
"kind": "KubeDirectorApp",
"metadata": {
"name" : "spark221e2"
},
"spec" : {
"systemctlMounts": true,
"config": {
"node_services": [
{
"service_ids": [
"ssh",
"spark",
"spark_master",
"spark_worker"
],
…
應用程式叢集的組態稱為 KubeDirectorCluster 資源。範例 Spark 2.2.1 叢集的 KubeDirectorCluster 定義位於檔案 kubedirector/deploy/example_clusters/cr-cluster-spark221.e1.yaml 中。
~> cat kubedirector/deploy/example_clusters/cr-cluster-spark221.e1.yaml
apiVersion: "kubedirector.bluedata.io/v1alpha1"
kind: "KubeDirectorCluster"
metadata:
name: "spark221e2"
spec:
app: spark221e2
roles:
- name: controller
replicas: 1
resources:
requests:
memory: "4Gi"
cpu: "2"
limits:
memory: "4Gi"
cpu: "2"
- name: worker
replicas: 2
resources:
requests:
memory: "4Gi"
cpu: "2"
limits:
memory: "4Gi"
cpu: "2"
- name: jupyter
…
在 Kubernetes 上使用 KubeDirector 執行 Spark
透過 KubeDirector,可以輕鬆地在 Kubernetes 上執行 Spark 叢集。
首先,使用命令 kubectl version 驗證 Kubernetes (1.9 或更新版本) 正在執行中
~> kubectl version
Client Version: version.Info{Major:"1", Minor:"11", GitVersion:"v1.11.3", GitCommit:"a4529464e4629c21224b3d52edfe0ea91b072862", GitTreeState:"clean", BuildDate:"2018-09-09T18:02:47Z", GoVersion:"go1.10.3", Compiler:"gc", Platform:"linux/amd64"}
Server Version: version.Info{Major:"1", Minor:"11", GitVersion:"v1.11.3", GitCommit:"a4529464e4629c21224b3d52edfe0ea91b072862", GitTreeState:"clean", BuildDate:"2018-09-09T17:53:03Z", GoVersion:"go1.10.3", Compiler:"gc", Platform:"linux/amd64"}
使用以下命令部署 KubeDirector 服務和範例 KubeDirectorApp 資源定義
cd kubedirector
make deploy
這些命令將啟動 KubeDirector Pod
~> kubectl get pods
NAME READY STATUS RESTARTS AGE
kubedirector-58cf59869-qd9hb 1/1 Running 0 1m
使用 kubectl get KubeDirectorApp 列出已安裝的 KubeDirector 應用程式
~> kubectl get KubeDirectorApp
NAME AGE
cassandra311 30m
spark211up 30m
spark221e2 30m
現在您可以使用範例 KubeDirectorCluster 檔案和 kubectl create -f deploy/example_clusters/cr-cluster-spark211up.yaml 命令啟動 Spark 2.2.1 叢集。驗證 Spark 叢集已啟動
~> kubectl get pods
NAME READY STATUS RESTARTS AGE
kubedirector-58cf59869-djdwl 1/1 Running 0 19m
spark221e2-controller-zbg4d-0 1/1 Running 0 23m
spark221e2-jupyter-2km7q-0 1/1 Running 0 23m
spark221e2-worker-4gzbz-0 1/1 Running 0 23m
spark221e2-worker-4gzbz-1 1/1 Running 0 23m
現在執行的服務包含 Spark 服務
~> kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubedirector ClusterIP 10.98.234.194 <none> 60000/TCP 1d
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 1d
svc-spark221e2-5tg48 ClusterIP None <none> 8888/TCP 21s
svc-spark221e2-controller-tq8d6-0 NodePort 10.104.181.123 <none> 22:30534/TCP,8080:31533/TCP,7077:32506/TCP,8081:32099/TCP 20s
svc-spark221e2-jupyter-6989v-0 NodePort 10.105.227.249 <none> 22:30632/TCP,8888:30355/TCP 20s
svc-spark221e2-worker-d9892-0 NodePort 10.107.131.165 <none> 22:30358/TCP,8081:32144/TCP 20s
svc-spark221e2-worker-d9892-1 NodePort 10.110.88.221 <none> 22:30294/TCP,8081:31436/TCP 20s
將瀏覽器指向連接埠 31533 將連接到 Spark Master UI
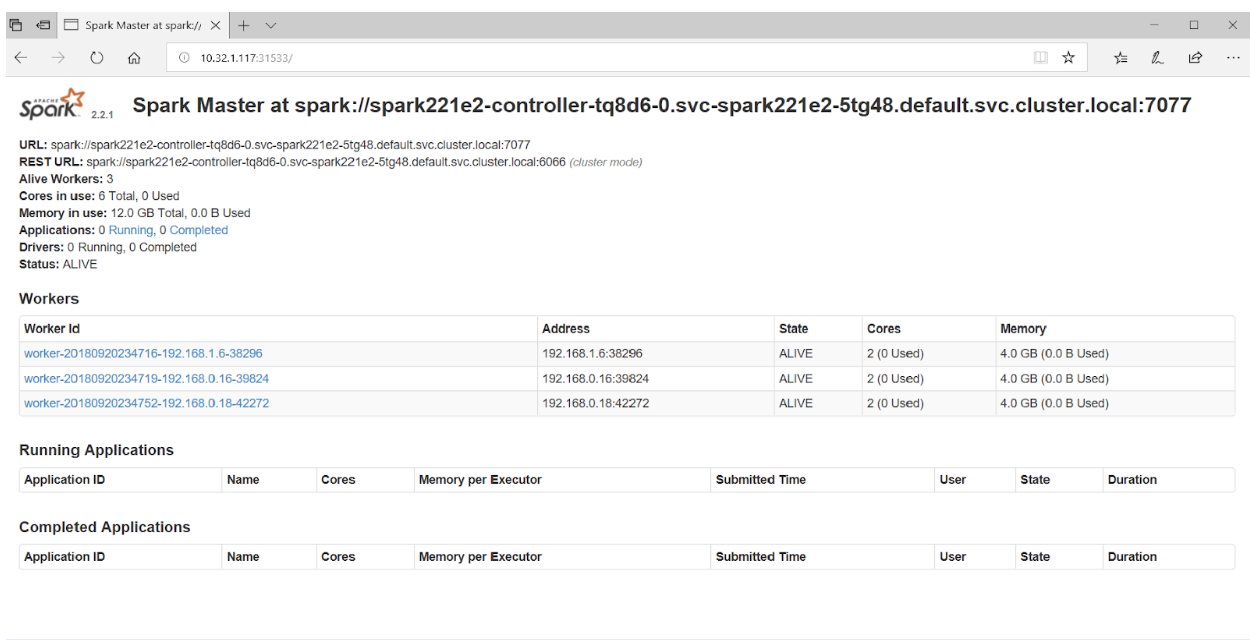
就這樣!事實上,在上面的範例中,我們也與 Spark 叢集一起部署了 Jupyter Notebook。
若要啟動另一個應用程式 (例如 Cassandra),只需指定另一個 KubeDirectorApp 檔案
kubectl create -f deploy/example_clusters/cr-cluster-cassandra311.yaml
查看正在執行的 Cassandra 叢集
~> kubectl get pods
NAME READY STATUS RESTARTS AGE
cassandra311-seed-v24r6-0 1/1 Running 0 1m
cassandra311-seed-v24r6-1 1/1 Running 0 1m
cassandra311-worker-rqrhl-0 1/1 Running 0 1m
cassandra311-worker-rqrhl-1 1/1 Running 0 1m
kubedirector-58cf59869-djdwl 1/1 Running 0 1d
spark221e2-controller-tq8d6-0 1/1 Running 0 22m
spark221e2-jupyter-6989v-0 1/1 Running 0 22m
spark221e2-worker-d9892-0 1/1 Running 0 22m
spark221e2-worker-d9892-1 1/1 Running 0 22m
現在您有一個 Spark 叢集 (包含 Jupyter Notebook) 和一個 Cassandra 叢集在 Kubernetes 上執行。使用 kubectl get service 查看服務集。
~> kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubedirector ClusterIP 10.98.234.194 <none> 60000/TCP 1d
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 1d
svc-cassandra311-seed-v24r6-0 NodePort 10.96.94.204 <none> 22:31131/TCP,9042:30739/TCP 3m
svc-cassandra311-seed-v24r6-1 NodePort 10.106.144.52 <none> 22:30373/TCP,9042:32662/TCP 3m
svc-cassandra311-vhh29 ClusterIP None <none> 8888/TCP 3m
svc-cassandra311-worker-rqrhl-0 NodePort 10.109.61.194 <none> 22:31832/TCP,9042:31962/TCP 3m
svc-cassandra311-worker-rqrhl-1 NodePort 10.97.147.131 <none> 22:31454/TCP,9042:31170/TCP 3m
svc-spark221e2-5tg48 ClusterIP None <none> 8888/TCP 24m
svc-spark221e2-controller-tq8d6-0 NodePort 10.104.181.123 <none> 22:30534/TCP,8080:31533/TCP,7077:32506/TCP,8081:32099/TCP 24m
svc-spark221e2-jupyter-6989v-0 NodePort 10.105.227.249 <none> 22:30632/TCP,8888:30355/TCP 24m
svc-spark221e2-worker-d9892-0 NodePort 10.107.131.165 <none> 22:30358/TCP,8081:32144/TCP 24m
svc-spark221e2-worker-d9892-1 NodePort 10.110.88.221 <none> 22:30294/TCP,8081:31436/TCP 24m
參與其中
KubeDirector 是一個完全開放原始碼、Apache v2 授權的專案 – 是我們稱為 BlueK8s 的更廣泛倡議中的第一個開放原始碼專案。KubeDirector 的 pre-alpha 程式碼剛剛發布,我們非常歡迎您加入不斷成長的開發人員、貢獻者和採用者社群。在 Twitter 上追蹤 @BlueK8s,並透過以下管道參與
- KubeDirector Slack 上的聊天室
- KubeDirector GitHub 儲存庫