本文已超過一年。較舊的文章可能包含過時的內容。請檢查頁面中的資訊自發布以來是否已變得不正確。
Kubernetes Topology 管理器移至 Beta 版 - 調整向上!
這篇部落格文章描述了 TopologyManager,這是 Kubernetes 1.18 版本中的 Beta 功能。TopologyManager 功能啟用了 CPU 和周邊設備(例如 SR-IOV VF 和 GPU)的 NUMA 對齊,讓您的工作負載可以在針對低延遲優化的環境中運行。
在引入 TopologyManager 之前,CPU 管理器和設備管理器會彼此獨立地做出資源分配決策。這可能會導致多插槽系統上出現不良的分配,從而導致延遲關鍵應用程式的效能下降。隨著 TopologyManager 的引入,我們現在有辦法避免這種情況。
這篇部落格文章涵蓋了
- NUMA 的簡要介紹以及它為何重要
- 最終使用者可用的策略,以確保 CPU 和設備的 NUMA 對齊
TopologyManager如何運作的內部細節TopologyManager目前的限制TopologyManager未來的方向
那麼,什麼是 NUMA,我為什麼要在意?
NUMA 術語代表非均勻記憶體存取 (Non-Uniform Memory Access)。它是一種在多 CPU 系統上可用的技術,允許不同的 CPU 以不同的速度存取不同的記憶體部分。任何直接連接到 CPU 的記憶體都被認為是該 CPU 的「本地」記憶體,並且可以非常快速地存取。任何未直接連接到 CPU 的記憶體都被認為是「非本地」記憶體,並且其存取時間會有所不同,具體取決於為了到達它必須經過多少個互連。在現代系統上,「本地」與「非本地」記憶體的概念也可以擴展到週邊設備,例如 NIC 或 GPU。為了獲得高效能,應該分配 CPU 和設備,以便它們可以存取相同的本地記憶體。
NUMA 系統上的所有記憶體都分為一組「NUMA 節點」,每個節點代表一組 CPU 或設備的本地記憶體。當個別 CPU 的本地記憶體與該 NUMA 節點關聯時,我們將其稱為 NUMA 節點的一部分。
我們根據為了到達週邊設備必須經過的最短互連數量,將週邊設備稱為 NUMA 節點的一部分。
例如,在圖 1 中,CPU 0-3 被稱為 NUMA 節點 0 的一部分,而 CPU 4-7 是 NUMA 節點 1 的一部分。同樣地,GPU 0 和 NIC 0 被稱為 NUMA 節點 0 的一部分,因為它們連接到 Socket 0,其 CPU 都是 NUMA 節點 0 的一部分。GPU 1 和 NIC 1 在 NUMA 節點 1 上也是如此。
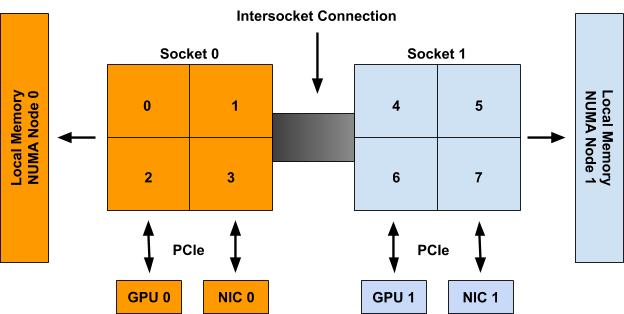
圖 1: 具有 2 個 NUMA 節點、2 個 Socket,每個 Socket 有 4 個 CPU、2 個 GPU 和 2 個 NIC 的範例系統。Socket 0 上的 CPU、GPU 0 和 NIC 0 都是 NUMA 節點 0 的一部分。Socket 1 上的 CPU、GPU 1 和 NIC 1 都是 NUMA 節點 1 的一部分。
雖然上面的範例顯示 NUMA 節點到 Socket 的 1 對 1 映射,但在一般情況下不一定是這樣。單個 NUMA 節點上可能有多個插槽,或者單個插槽的個別 CPU 可能連接到不同的 NUMA 節點。此外,新興技術(例如 Sub-NUMA Clustering (Sub-NUMA 叢集) (在最近的 intel CPU 上可用))允許單個 CPU 與多個 NUMA 節點關聯,只要它們對兩個節點的記憶體存取時間相同(或差異可忽略不計)。
TopologyManager 的構建旨在處理所有這些情況。
對齊向上!這是一項團隊努力!
如先前所述,TopologyManager 允許使用者通過 NUMA 節點對齊其 CPU 和週邊設備分配。有多種策略可用於此目的
none:此策略不會嘗試執行任何資源對齊。它的行為與TopologyManager完全不存在時相同。這是預設策略。best-effort:使用此策略,TopologyManager將嘗試盡可能地在 NUMA 節點上對齊分配,但即使某些已分配的資源未在同一個 NUMA 節點上對齊,也始終允許 Pod 啟動。restricted:此策略與best-effort策略相同,不同之處在於,如果無法正確對齊已分配的資源,它將使 Pod 准入失敗。與single-numa-node策略不同,如果永遠無法在單個 NUMA 節點上滿足分配請求(例如,請求了 2 個設備,而系統上僅有的 2 個設備位於不同的 NUMA 節點上),則某些分配可能來自多個 NUMA 節點。single-numa-node:此策略是最嚴格的,並且僅當所有請求的 CPU 和設備都可以從恰好一個 NUMA 節點分配時,才允許 Pod 准入。
重要的是要注意,選定的策略是單獨應用於 Pod 規格中的每個容器,而不是跨所有容器一起對齊資源。
此外,單個策略透過全域 kubelet 標誌應用於節點上的所有 Pod,而不是允許使用者在每個 Pod 的基礎上(或每個容器的基礎上)選擇不同的策略。我們希望在未來放寬此限制。
以下可以看到設定這些策略之一的 kubelet 標誌
--topology-manager-policy=
[none | best-effort | restricted | single-numa-node]
此外,TopologyManager 受功能閘道保護。此功能閘道自 Kubernetes 1.16 起可用,但自 1.18 起才預設啟用。
可以如下啟用或停用功能閘道(如 此處 更詳細的描述)
--feature-gates="...,TopologyManager=<true|false>"
為了根據選定的策略觸發對齊,使用者必須根據一組特定的要求在其 Pod 規格中請求 CPU 和週邊設備。
對於週邊設備,這意味著從設備外掛程式提供的可用資源中請求設備(例如 intel.com/sriov、nvidia.com/gpu 等)。這僅在設備外掛程式已擴展為與 TopologyManager 正確整合時才有效。目前,已知具有此擴展的唯一外掛程式是 Nvidia GPU 設備外掛程式 和 Intel SRIOV 網路設備外掛程式。有關如何擴展設備外掛程式以與 TopologyManager 整合的詳細資訊,請參閱 此處。
對於 CPU,這需要 CPUManager 已配置為啟用其 --static 策略,並且 Pod 在 Guaranteed QoS 類別中運行(即,所有 CPU 和記憶體 limits 等於其各自的 CPU 和記憶體 requests)。CPU 也必須以整數值請求(例如 1、2、1000m 等)。有關如何設定 CPUManager 策略的詳細資訊,請參閱 此處。
例如,假設 CPUManager 正在啟用其 --static 策略的情況下運行,並且 gpu-vendor.com 和 nic-vendor.com 的設備外掛程式已擴展為與 TopologyManager 正確整合,則以下 Pod 規格足以觸發 TopologyManager 運行其選定的策略
spec:
containers:
- name: numa-aligned-container
image: alpine
resources:
limits:
cpu: 2
memory: 200Mi
gpu-vendor.com/gpu: 1
nic-vendor.com/nic: 1
依照前一節的圖 1,這將導致以下對齊的分配之一
{cpu: {0, 1}, gpu: 0, nic: 0}
{cpu: {0, 2}, gpu: 0, nic: 0}
{cpu: {0, 3}, gpu: 0, nic: 0}
{cpu: {1, 2}, gpu: 0, nic: 0}
{cpu: {1, 3}, gpu: 0, nic: 0}
{cpu: {2, 3}, gpu: 0, nic: 0}
{cpu: {4, 5}, gpu: 1, nic: 1}
{cpu: {4, 6}, gpu: 1, nic: 1}
{cpu: {4, 7}, gpu: 1, nic: 1}
{cpu: {5, 6}, gpu: 1, nic: 1}
{cpu: {5, 7}, gpu: 1, nic: 1}
{cpu: {6, 7}, gpu: 1, nic: 1}
就是這樣!只需遵循此模式,即可讓 TopologyManager 確保跨請求拓撲感知設備和獨佔 CPU 的容器進行 NUMA 對齊。
注意: 如果 Pod 因 TopologyManager 策略之一而被拒絕,它將被置於 Terminated 狀態,並顯示 Pod 准入錯誤和「TopologyAffinityError」的原因。一旦 Pod 處於此狀態,Kubernetes 調度器將不會嘗試重新調度它。因此,建議使用具有副本的 Deployment,以觸發在此類故障時重新部署 Pod。也可以實作 外部控制迴圈,以觸發重新部署具有 TopologyAffinityError 的 Pod。
這很棒,那麼它在底層是如何運作的?
以下可以看到 TopologyManager 執行的主要邏輯的虛擬碼
for container := range append(InitContainers, Containers...) {
for provider := range HintProviders {
hints += provider.GetTopologyHints(container)
}
bestHint := policy.Merge(hints)
for provider := range HintProviders {
provider.Allocate(container, bestHint)
}
}
以下圖表總結了此迴圈期間採取的步驟
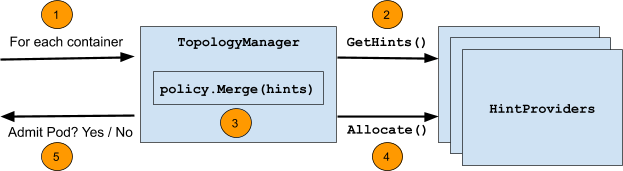
這些步驟本身是
- 迴圈遍歷 Pod 中的所有容器。
- 對於每個容器,從一組「
HintProviders」為容器請求的每個拓撲感知資源類型(例如gpu-vendor.com/gpu、nic-vendor.com/nic、cpu等)收集「TopologyHints」。 - 使用選定的策略,合併收集到的
TopologyHints,以找到在所有資源類型之間對齊資源分配的「最佳」提示。 - 迴圈回到提示提供者集合,指示它們使用合併的提示作為指導來分配它們控制的資源。
- 此迴圈在 Pod 准入時運行,如果這些步驟中的任何一個失敗或無法根據選定的策略滿足對齊,則將無法准入 Pod。在失敗之前分配的任何資源都會相應地清理。
以下章節更詳細地介紹了 TopologyHints 和 HintProviders 的確切結構,以及每個策略使用的合併策略的一些詳細資訊。
TopologyHints
TopologyHint 編碼了一組約束,可以從中滿足給定的資源請求。目前,我們考慮的唯一約束是 NUMA 對齊。它的定義如下
type TopologyHint struct {
NUMANodeAffinity bitmask.BitMask
Preferred bool
}
NUMANodeAffinity 欄位包含可以滿足資源請求的 NUMA 節點的位元遮罩。例如,在具有 2 個 NUMA 節點的系統上,可能的遮罩包括
{00}, {01}, {10}, {11}
Preferred 欄位包含一個布林值,用於編碼給定的提示是否為「首選」。對於 best-effort 策略,在生成「最佳」提示時,首選提示將優先於非首選提示。對於 restricted 和 single-numa-node 策略,將拒絕非首選提示。
通常,HintProviders 通過查看可以滿足資源請求的當前可用資源集來生成 TopologyHints。更具體地說,它們為可以滿足該資源請求的每個可能的 NUMA 節點遮罩生成一個 TopologyHint。如果遮罩無法滿足請求,則會省略它。例如,當被要求分配 2 個資源時,HintProvider 可能在具有 2 個 NUMA 節點的系統上提供以下提示。這些提示編碼了兩個資源可以來自單個 NUMA 節點(節點 0 或節點 1),或者它們可以各自來自不同的 NUMA 節點(但我們更希望它們僅來自一個節點)。
{01: True}, {10: True}, {11: False}
目前,當且僅當 NUMANodeAffinity 編碼可以滿足資源請求的最小 NUMA 節點集時,所有 HintProviders 都將 Preferred 欄位設定為 True。通常,這僅適用於 TopologyHints,其位元遮罩中設定了單個 NUMA 節點。但是,如果永遠滿足資源請求的唯一方法是跨越多個 NUMA 節點(例如,請求了 2 個設備,而系統上僅有的 2 個設備位於不同的 NUMA 節點上),則它也可能為 True。
{0011: True}, {0111: False}, {1011: False}, {1111: False}
注意: 以這種方式設定 Preferred 欄位不是基於當前可用資源集。它是基於在某些最小 NUMA 節點集上物理分配請求的資源數量的能力。
透過這種方式,如果直到其他容器釋放其資源才能滿足實際的首選分配,則 HintProvider 可能會傳回一個提示列表,其中所有 Preferred 欄位都設定為 False。例如,考慮圖 1 中系統的以下場景
- 除了 2 個 CPU 外,所有 CPU 目前都已分配給容器
- 剩餘的 2 個 CPU 位於不同的 NUMA 節點上
- 一個新的容器出現,要求 2 個 CPU
在這種情況下,唯一生成的提示將是 {11: False} 而不是 {11: True}。發生這種情況是因為可以在此系統上的同一個 NUMA 節點分配 2 個 CPU(只是現在不行,考慮到目前的分配狀態)。想法是,當可以滿足最小對齊時,最好讓 Pod 准入失敗並重試部署,而不是允許調度具有次優對齊的 Pod。
HintProviders
HintProvider 是 kubelet 內部的一個組件,它與 TopologyManager 協調對齊的資源分配。目前,Kubernetes 中唯一的 HintProviders 是 CPUManager 和 DeviceManager。我們計劃很快新增對 HugePages 的支援。
如先前所述,TopologyManager 既從 HintProviders 收集 TopologyHints,又使用合併的「最佳」提示觸發它們上的對齊資源分配。因此,HintProviders 實作了以下介面
type HintProvider interface {
GetTopologyHints(*v1.Pod, *v1.Container) map[string][]TopologyHint
Allocate(*v1.Pod, *v1.Container) error
}
請注意,對 GetTopologyHints() 的呼叫傳回了 map[string][]TopologyHint。這允許單個 HintProvider 為多種資源類型提供提示,而不僅僅是一種。例如,DeviceManager 需要這樣做,以便為其外掛程式註冊的每種資源類型傳回提示。
當 HintProviders 生成其提示時,它們僅考慮如何在系統上當前可用資源的情況下滿足對齊。不考慮已分配給其他容器的任何資源。
例如,考慮圖 1 中的系統,以下兩個容器從中請求資源
Container0 | Container1 |
spec:
containers:
- name: numa-aligned-container0
image: alpine
resources:
limits:
cpu: 2
memory: 200Mi
gpu-vendor.com/gpu: 1
nic-vendor.com/nic: 1
| spec:
containers:
- name: numa-aligned-container1
image: alpine
resources:
limits:
cpu: 2
memory: 200Mi
gpu-vendor.com/gpu: 1
nic-vendor.com/nic: 1
|
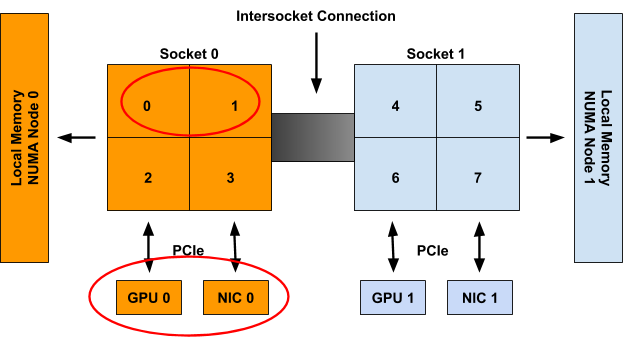
如果 Container0 是系統上第一個被考慮分配的容器,則將為規格中的三種拓撲感知資源類型生成以下提示集。
cpu: {{01: True}, {10: True}, {11: False}}
gpu-vendor.com/gpu: {{01: True}, {10: True}}
nic-vendor.com/nic: {{01: True}, {10: True}}
結果對齊分配為
{cpu: {0, 1}, gpu: 0, nic: 0}
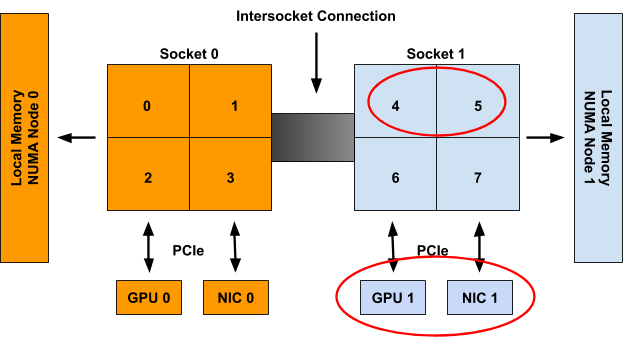
在考慮 Container1 時,這些資源被認為是不可用的,因此只會生成以下提示集
cpu: {{01: True}, {10: True}, {11: False}}
gpu-vendor.com/gpu: {{10: True}}
nic-vendor.com/nic: {{10: True}}
結果對齊分配為
{cpu: {4, 5}, gpu: 1, nic: 1}
注意: 與本節開頭提供的虛擬碼不同,對 Allocate() 的呼叫實際上並未直接採用合併的「最佳」提示的參數。相反,TopologyManager 實作了以下 Store 介面,HintProviders 可以查詢該介面以檢索為特定容器生成的提示(一旦生成)
type Store interface {
GetAffinity(podUID string, containerName string) TopologyHint
}
將其分離到自己的 API 呼叫中,允許在 Pod 准入迴圈之外存取此提示。這對於調試以及在 kubectl 等工具中報告生成的提示很有用(尚不可用)。
Policy.Merge
給定策略定義的合併策略決定了它如何將所有 HintProviders 生成的 TopologyHints 集合合併為單個 TopologyHint,該提示可用於通知對齊的資源分配。
所有支援策略的一般合併策略都以相同的方式開始
- 取得為每種資源類型生成的
TopologyHints的交叉乘積 - 對於交叉乘積中的每個條目,將每個
TopologyHint的 NUMA 親和性進行位元與運算。將其設定為結果「合併」提示中的 NUMA 親和性。 - 如果條目中的所有提示都將
Preferred設定為True,則在結果「合併」提示中將Preferred設定為True。 - 如果條目中的即使一個提示將
Preferred設定為False,則在結果「合併」提示中將Preferred設定為False。如果「合併」提示的 NUMA 親和性包含所有 0,也將Preferred設定為False。
依照上一節的範例,為 Container0 生成的提示為
cpu: {{01: True}, {10: True}, {11: False}}
gpu-vendor.com/gpu: {{01: True}, {10: True}}
nic-vendor.com/nic: {{01: True}, {10: True}}
上面的演算法產生以下交叉乘積條目和「合併」提示集
| 交叉乘積條目
| 「合併」提示 |
{{01: True}, {01: True}, {01: True}} | {01: True} |
{{01: True}, {01: True}, {10: True}} | {00: False} |
{{01: True}, {10: True}, {01: True}} | {00: False} |
{{01: True}, {10: True}, {10: True}} | {00: False} |
{{10: True}, {01: True}, {01: True}} | {00: False} |
{{10: True}, {01: True}, {10: True}} | {00: False} |
{{10: True}, {10: True}, {01: True}} | {00: False} |
{{10: True}, {10: True}, {10: True}} | {01: True} |
{{11: False}, {01: True}, {01: True}} | {01: False} |
{{11: False}, {01: True}, {10: True}} | {00: False} |
{{11: False}, {10: True}, {01: True}} | {00: False} |
{{11: False}, {10: True}, {10: True}} | {10: False} |
一旦生成此「合併」提示列表,就由正在使用的特定 TopologyManager 策略來決定將哪個提示視為「最佳」提示。
一般來說,這涉及
- 按其「狹窄度」對合併的提示進行排序。「狹窄度」定義為提示的 NUMA 親和性遮罩中設定的位元數。設定的位元越少,提示越窄。對於 NUMA 親和性遮罩中設定的位元數相同的提示,設定了最多低位位元的提示被認為更窄。
- 按其
Preferred欄位對合併的提示進行排序。將Preferred設定為True的提示被認為比將Preferred設定為False的提示更有可能成為候選提示。 - 選擇對
Preferred的最佳可能設定具有最狹窄的提示。
在 best-effort 策略的情況下,此演算法將始終導致某些提示被選為「最佳」提示,並且 Pod 被准入。然後,此「最佳」提示可供 HintProviders 使用,以便它們可以根據它進行資源分配。
但是,在 restricted 和 single-numa-node 策略的情況下,任何將 Preferred 設定為 False 的選定提示都將立即被拒絕,導致 Pod 准入失敗且不分配任何資源。此外,single-numa-node 也將拒絕在其親和性遮罩中設定了多個 NUMA 節點的選定提示。
在上面的範例中,Pod 將被所有策略以 {01: True} 的提示准入。
即將推出的增強功能
雖然 1.18 版本和升級到 Beta 版本帶來了一些出色的增強功能和修復,但仍然存在許多限制,請參閱 此處 描述。我們已經在著手解決這些限制以及更多問題。
本節將逐步說明我們計劃在不久的將來為 TopologyManager 實作的增強功能集。此列表並非詳盡無遺,但它能讓您清楚了解我們的前進方向。它會依據我們預期完成各項增強功能的時程來排序。
如果您想參與協助進行任何這些增強功能,請加入每週 Kubernetes SIG-node 會議以了解更多資訊,並成為社群努力的一份子!
支援裝置特定的限制
目前,NUMA 親緣性是 TopologyManager 針對資源對齊所考量的唯一限制。此外,可以對 TopologyHint 進行的唯一可擴充的擴展涉及節點層級的限制,例如跨裝置類型的 PCIe 匯流排對齊。嘗試將任何裝置特定的限制新增至此結構(例如一組 GPU 裝置之間的內部 NVLINK 拓撲)將難以處理。
因此,我們提出對裝置外掛程式介面的擴展,讓外掛程式能夠聲明其拓撲感知配置偏好,而無需向 kubelet 公開任何裝置特定的拓撲資訊。透過這種方式,TopologyManager 可以限制為僅處理常見的節點層級拓撲限制,同時仍然能夠將裝置特定的拓撲限制納入其配置決策中。
此提案的詳細資訊可以在此處找到,並且應盡快在 Kubernetes 1.19 中提供。
hugepages 的 NUMA 對齊
如先前所述,目前 TopologyManager 可用的唯二 HintProviders 是 CPUManager 和 DeviceManager。然而,目前正在進行新增對 hugepages 支援的工作。隨著這項工作的完成,TopologyManager 最終將能夠在同一個 NUMA 節點上配置記憶體、hugepages、CPU 和 PCI 裝置。
目前正在審查針對此工作的 KEP,並且正在進行原型設計,以便盡快實作此功能。
排程器感知
目前,TopologyManager 充當 Pod 准入控制器。它並未直接參與 Pod 將放置在哪裡的排程決策。相反地,當 Kubernetes 排程器(或部署中執行的任何排程器)將 Pod 放置在節點上執行時,TopologyManager 將決定是否應「允許」或「拒絕」Pod。如果 Pod 因為缺少可用的 NUMA 對齊資源而被拒絕,情況可能會變得有點有趣。這個 Kubernetes issue 很好地突顯並討論了這種情況。
那麼我們該如何解決這個限制呢?我們有 Kubernetes 排程框架 來救援!此框架提供一組新的外掛程式 API,與現有的 Kubernetes 排程器整合,並允許實作排程功能(例如 NUMA 對齊),而無需訴諸其他可能較不吸引人的替代方案,包括編寫您自己的排程器,甚至更糟的是,建立分支以新增您自己的排程器秘密武器。
如何實作這些擴展以與 TopologyManager 整合的詳細資訊尚未制定。我們仍然需要回答以下問題:
- 我們是否需要在
TopologyManager和排程器中複製邏輯來判斷裝置親緣性? - 我們是否需要新的 API 從
TopologyManager取得TopologyHints到排程器外掛程式?
此功能的工作應在未來幾個月內開始,敬請期待!
每個 Pod 的對齊策略
如先前所述,單一策略透過全域 kubelet 標誌應用於節點上的所有 Pod,而不是允許使用者在每個 Pod 的基礎上(或每個容器的基礎上)選擇不同的策略。
雖然我們同意這將會是一項很棒的功能,但在實現它之前,需要克服相當多的障礙。最大的障礙是,此增強功能將需要 API 變更,才能在 Pod 規格或其關聯的 RuntimeClass 中表達所需的對齊策略。
我們現在才剛開始針對此功能進行認真的討論,而且即使進展順利,也還需要幾個版本才能推出。
結論
隨著 TopologyManager 在 1.18 版本中升級為 Beta 版,我們鼓勵大家試用,並期待您可能有的任何意見回饋。在過去的幾個版本中,我們已經努力進行了許多修正和增強,大幅改善了 TopologyManager 及其 HintProviders 的功能和可靠性。雖然仍然存在許多限制,但我們已計劃了一系列增強功能來解決這些限制,並期待在即將發布的版本中為您提供許多新功能。
如果您對其他增強功能有任何想法,或對某些功能有需求,請隨時告訴我們。團隊始終樂於接受增強和改進 TopologyManager 的建議。
我們希望您覺得這篇部落格文章內容豐富且實用!如果您有任何問題或意見,請告訴我們。祝您部署愉快……對齊!