本文已超過一年。較舊的文章可能包含過時的內容。請檢查頁面中的資訊自發布以來是否已變得不正確。
介紹 PodTopologySpread
管理 Pod 在叢集中的分佈非常困難。眾所周知的 Kubernetes Pod 親和性和反親和性功能,允許在不同拓撲中對 Pod 放置進行一些控制。但是,這些功能僅解決了 Pod 分佈用例的一部分:要么將無限數量的 Pod 放置到單個拓撲中,要么不允許兩個 Pod 在同一拓撲中共存。在這兩個極端情況之間,通常需要將 Pod 均勻分佈在拓撲中,以便實現更好的叢集利用率和應用程式的高可用性。
PodTopologySpread 排程外掛程式(最初提議為 EvenPodsSpread)旨在填補該空白。我們在 1.18 版本中將其升級為 beta 版。
API 變更
在 Pod 的 spec API 中引入了一個新的欄位 topologySpreadConstraints。
spec:
topologySpreadConstraints:
- maxSkew: <integer>
topologyKey: <string>
whenUnsatisfiable: <string>
labelSelector: <object>
由於此 API 嵌入在 Pod 的 spec 中,因此您可以在所有高階工作負載 API 中使用此功能,例如 Deployment、DaemonSet、StatefulSet 等。
讓我們看一個叢集範例來理解此 API。
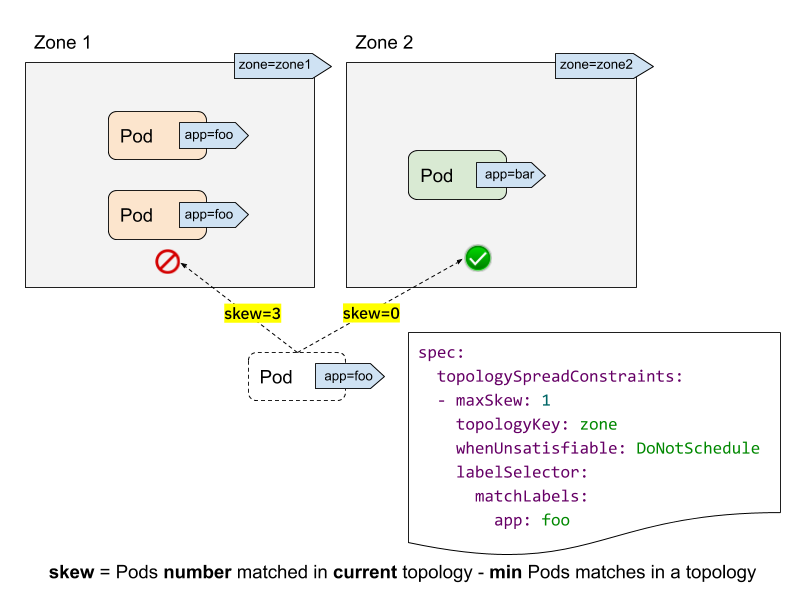
- labelSelector 用於尋找符合條件的 Pod。對於每個拓撲,我們計算符合此標籤選擇器的 Pod 數量。在上面的範例中,給定 labelSelector 為 "app: foo","zone1" 中的匹配數為 2;而 "zone2" 中的數量為 0。
- topologyKey 是在節點標籤中定義拓撲的鍵。在上面的範例中,如果某些節點具有 "zone=zone1" 標籤,則將其分組到 "zone1" 中;而其他節點則分組到 "zone2" 中。
- maxSkew 描述了 Pod 可以不均勻分佈的最大程度。在上面的範例中
- 如果我們將傳入的 Pod 放置到 "zone1",則 "zone1" 上的偏差將變為 3("zone1" 中匹配了 3 個 Pod;"zone2" 中匹配的 Pod 全域最小值為 0),這違反了 "maxSkew: 1" 限制。
- 如果將傳入的 Pod 放置到 "zone2",則 "zone2" 上的偏差為 0("zone2" 中匹配了 1 個 Pod;"zone2" 本身匹配的 Pod 全域最小值為 1),這滿足了 "maxSkew: 1" 限制。請注意,偏差是針對每個合格的節點計算的,而不是全域偏差。
- whenUnsatisfiable 指定當無法滿足 "maxSkew" 時,應採取什麼措施
DoNotSchedule(預設值)告訴排程器不要排程它。這是一個硬性限制。ScheduleAnyway告訴排程器仍然排程它,同時優先考慮減少偏差的節點。這是一個軟性限制。
進階用法
正如功能名稱 "PodTopologySpread" 所暗示的那樣,此功能的基本用法是以絕對均勻的方式 (maxSkew=1) 或相對均勻的方式 (maxSkew>=2) 執行您的工作負載。有關更多詳細資訊,請參閱官方文件。
除了這種基本用法之外,還有一些進階用法範例,使您的工作負載能夠在高可用性和叢集利用率方面受益。
與 NodeSelector / NodeAffinity 一起使用
您可能已經發現我們沒有 "topologyValues" 欄位來限制 Pod 將要排程到的拓撲。預設情況下,它將搜尋所有節點並按 "topologyKey" 對其進行分組。有時這可能不是理想的情況。例如,假設有一個叢集,其中的節點標記為 "env=prod"、"env=staging" 和 "env=qa",現在您想要跨區域將 Pod 均勻地放置到 "qa" 環境中,這可能嗎?
答案是肯定的。您可以利用 NodeSelector 或 NodeAffinity API 規範。在底層,PodTopologySpread 功能將尊重這一點,並在滿足選擇器的節點之間計算分佈限制。
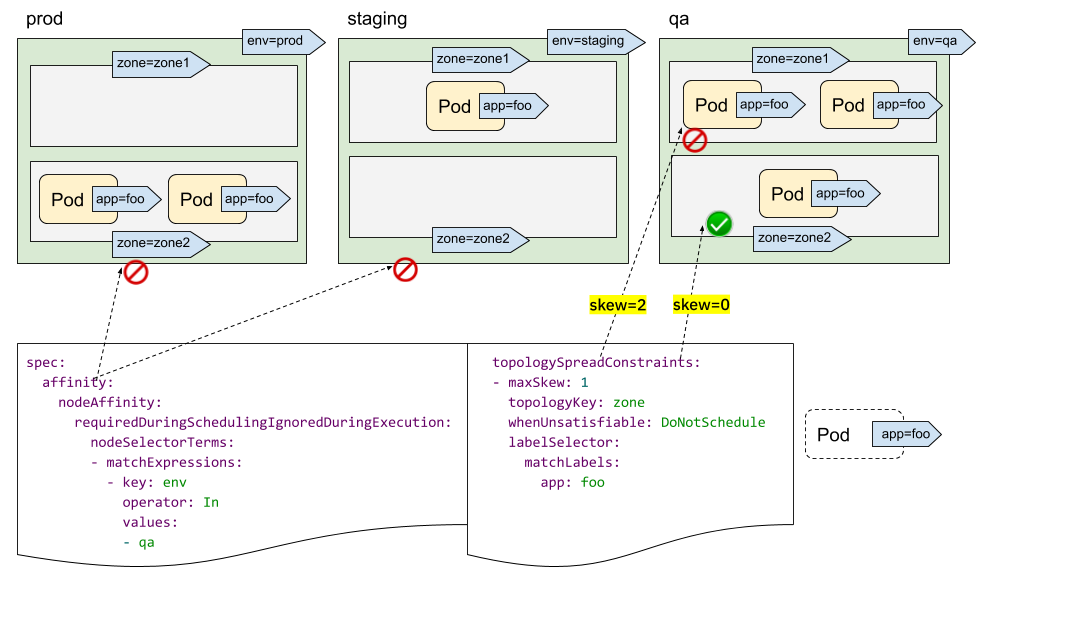
如上圖所示,您可以指定 `spec.affinity.nodeAffinity` 將「搜尋範圍」限制為「qa」環境,並且在此範圍內,Pod 將排程到滿足 topologySpreadConstraints 的區域。在這種情況下,它是 "zone2"。
多個 TopologySpreadConstraints
直觀地理解單個 TopologySpreadConstraint 的工作原理。多個 TopologySpreadConstraints 的情況又是如何呢?在內部,每個 TopologySpreadConstraint 都是獨立計算的,結果集將被合併以產生最終的結果集 - 即,合適的節點。
在以下範例中,我們希望同時將 Pod 排程到具有 2 個要求的叢集
- 在區域之間均勻放置 Pod
- 在節點之間均勻放置 Pod
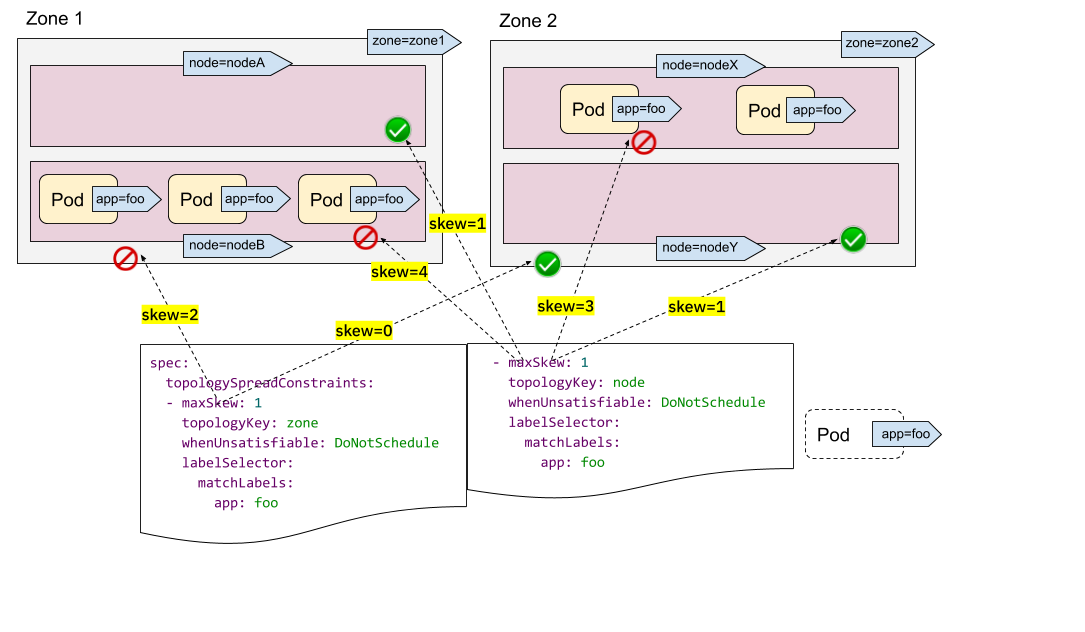
對於第一個限制,zone1 中有 3 個 Pod,zone2 中有 2 個 Pod,因此傳入的 Pod 只能放置到 zone2 以滿足 "maxSkew=1" 限制。換句話說,結果集是 nodeX 和 nodeY。
對於第二個限制,nodeB 和 nodeX 中有太多 Pod,因此傳入的 Pod 只能放置到 nodeA 和 nodeY。
現在我們可以得出結論,唯一合格的節點是 nodeY - 來自集合 {nodeX, nodeY}(來自第一個限制)和 {nodeA, nodeY}(來自第二個限制)的交集。
多個 TopologySpreadConstraints 功能強大,但請務必理解與前面的「NodeSelector/NodeAffinity」範例的區別:一個是獨立計算結果集然後相互連接;而另一個是根據節點約束的篩選結果計算 topologySpreadConstraints。
除了在所有 topologySpreadConstraints 中使用「硬性」限制外,您還可以結合使用「硬性」限制和「軟性」限制,以適應更多樣化的叢集情況。
注意
如果對同一個 {topologyKey, whenUnsatisfiable} 元組應用了兩個 TopologySpreadConstraints,則 Pod 建立將被阻止並返回驗證錯誤。PodTopologySpread 預設值
PodTopologySpread 是一個 Pod 層級 API。因此,要使用此功能,工作負載作者需要了解叢集的底層拓撲,然後在每個工作負載的 Pod spec 中指定適當的 `topologySpreadConstraints`。雖然 Pod 層級 API 提供了最大的靈活性,但也可以指定叢集層級的預設值。
預設的 PodTopologySpread 限制允許您為叢集中的所有工作負載指定分佈,並針對其拓撲進行客製化。操作員/管理員可以在啟動 kube-scheduler 時,在排程設定檔組態 API中將限制指定為 PodTopologySpread 外掛程式引數。
範例組態可能如下所示
apiVersion: kubescheduler.config.k8s.io/v1alpha2
kind: KubeSchedulerConfiguration
profiles:
pluginConfig:
- name: PodTopologySpread
args:
defaultConstraints:
- maxSkew: 1
topologyKey: example.com/rack
whenUnsatisfiable: ScheduleAnyway
在組態預設限制時,標籤選擇器必須留空。kube-scheduler 將從 Pod 到 Services、ReplicationControllers、ReplicaSets 或 StatefulSets 的成員資格中推斷出標籤選擇器。Pod 始終可以透過 PodSpec 提供自己的預設限制來覆寫預設限制。
注意
當使用預設的 PodTopologySpread 限制時,建議停用舊的 DefaultTopologySpread 外掛程式。總結
PodTopologySpread 允許您使用靈活且富有表現力的 Pod 層級 API 為您的工作負載定義分佈限制。過去,工作負載作者使用 Pod 反親和性規則來強制或提示排程器在每個拓撲域中執行單個 Pod。相比之下,新的 PodTopologySpread 限制允許 Pod 指定可以是必需的(硬性)或期望的(軟性)偏差級別。該功能可以與節點選擇器和節點親和性配對,以將分佈限制在特定域中。Pod 分佈限制可以針對不同的拓撲定義,例如主機名稱、區域、區域、機架等。
最後,叢集操作員可以定義要應用於所有 Pod 的預設限制。這樣,Pod 不需要知道叢集的底層拓撲。