本文已超過一年。較舊的文章可能包含過時的內容。請檢查頁面中的資訊自發布以來是否已變得不正確。
第三方裝置指標正式發佈
在 Kubernetes 1.20 中,管理大規模 Kubernetes 叢集基礎架構的團隊,將看到兩個令人興奮且期待已久的功能畢業
- Pod Resources API (在 1.13 中引入) 終於畢業到 GA。這允許 Kubernetes 外掛程式取得節點資源使用情況和分配的相關資訊;例如:哪個 Pod/容器消耗了哪個裝置。
DisableAcceleratorMetrics功能 (在 1.19 中引入) 正在畢業到 Beta 版,並且預設將啟用。這將移除 kubelet 報告的裝置指標,轉而使用新的外掛程式架構。
許多與基本裝置支援相關的功能 (裝置探索、外掛程式和監控) 正在達到高度穩定性。Kubernetes 使用者應將這些功能視為實現更複雜使用案例 (網路、排程、儲存等) 的墊腳石!
一個這樣的範例是非均勻記憶體存取 (NUMA) 位置,在選擇裝置時,應用程式通常希望確保 CPU 記憶體與裝置記憶體之間的資料傳輸盡可能快。在某些情況下,不正確的 NUMA 位置可能會抵銷將運算卸載到外部裝置的好處。
如果您對這些主題感興趣,請考慮加入 Kubernetes 節點特別興趣小組 (SIG),以了解所有與 Kubernetes 節點相關的主題、與執行階段相關主題的 COD (容器協調裝置) 工作小組,或與資源管理相關主題的資源管理論壇!
Pod Resources API - 為何需要存在?
Kubernetes 是一個廠商中立的平台。如果我們希望它支援裝置監控,則在 Kubernetes 程式碼庫中新增廠商特定的程式碼並非理想的解決方案。最終,裝置是一個需要深入專業知識的領域,而在此領域中新增和維護程式碼的最佳人選是裝置廠商本身。
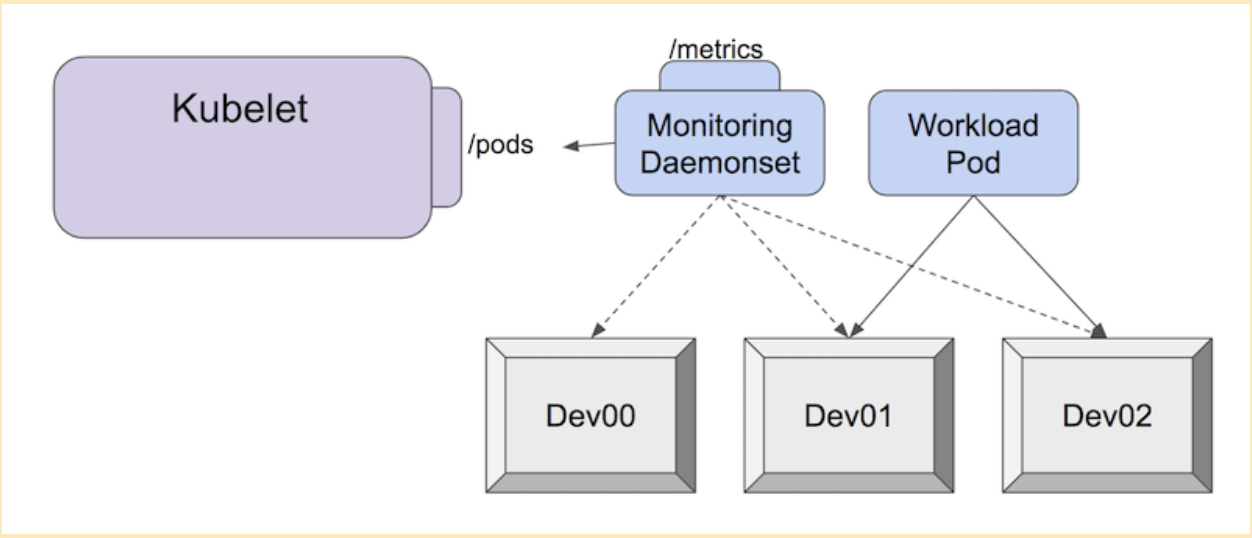
Pod Resources API 是為了解決此問題而建置的。每個廠商都可以建置和維護自己的樹狀結構外監控外掛程式。此監控外掛程式通常部署為叢集內的獨立 Pod,然後可以將裝置發出的指標與正在使用它的相關 Pod 建立關聯。
例如,使用 NVIDIA GPU dcgm-exporter 以 Prometheus 格式抓取指標
$ curl -sL http://127.0.01:8080/metrics
# HELP DCGM_FI_DEV_SM_CLOCK SM clock frequency (in MHz).
# TYPE DCGM_FI_DEV_SM_CLOCK gauge
# HELP DCGM_FI_DEV_MEM_CLOCK Memory clock frequency (in MHz).
# TYPE DCGM_FI_DEV_MEM_CLOCK gauge
# HELP DCGM_FI_DEV_MEMORY_TEMP Memory temperature (in C).
# TYPE DCGM_FI_DEV_MEMORY_TEMP gauge
...
DCGM_FI_DEV_SM_CLOCK{gpu="0", UUID="GPU-604ac76c-d9cf-fef3-62e9-d92044ab6e52",container="foo",namespace="bar",pod="baz"} 139
DCGM_FI_DEV_MEM_CLOCK{gpu="0", UUID="GPU-604ac76c-d9cf-fef3-62e9-d92044ab6e52",container="foo",namespace="bar",pod="baz"} 405
DCGM_FI_DEV_MEMORY_TEMP{gpu="0", UUID="GPU-604ac76c-d9cf-fef3-62e9-d92044ab6e52",container="foo",namespace="bar",pod="baz"} 9223372036854775794
每個代理程式都應遵守節點監控指南。換句話說,外掛程式應以 Prometheus 格式產生指標,並且新指標不應直接依賴 Kubernetes 基礎。
這允許指標的使用者使用相容的監控管線來收集和分析來自各種代理程式的指標,即使它們是由不同的廠商維護的。
停用 NVIDIA GPU 指標 - 警告
隨著外掛程式監控系統的畢業,Kubernetes 正在棄用 kubelet 報告的 NVIDIA GPU 指標。
隨著 Kubernetes 1.20 中預設啟用 DisableAcceleratorMetrics 功能,NVIDIA GPU 在 Kubernetes 中不再是特殊的公民。這在廠商中立的精神下是一件好事,並且讓最適合的人員能夠按照自己的發布時程維護他們的外掛程式!
使用者現在需要安裝 NVIDIA GDGM exporter 或使用 綁定 以收集有關 NVIDIA GPU 更準確和完整的指標。此棄用意味著您不能再依賴 kubelet 報告的指標,例如 container_accelerator_duty_cycle 或 container_accelerator_memory_used_bytes,這些指標用於收集 NVIDIA GPU 記憶體使用率。
這表示曾經依賴 kubelet 報告的 NVIDIA GPU 指標的使用者,將需要更新其參考並部署 NVIDIA 外掛程式。也就是說,Kubernetes 報告的不同指標對應到以下指標
| Kubernetes 指標 | NVIDIA dcgm-exporter 指標 |
|---|---|
container_accelerator_duty_cycle | DCGM_FI_DEV_GPU_UTIL |
container_accelerator_memory_used_bytes | DCGM_FI_DEV_FB_USED |
container_accelerator_memory_total_bytes | DCGM_FI_DEV_FB_FREE + DCGM_FI_DEV_FB_USED |
您可能也會對其他指標感興趣,例如 DCGM_FI_DEV_GPU_TEMP (GPU 溫度) 或 DCGM_FI_DEV_POWER_USAGE (功耗)。預設集可在 Nvidia 的 Data Center GPU Manager 文件中找到。
請注意,對於此版本,您仍然可以將 DisableAcceleratorMetrics 功能閘道 設定為 false,有效地重新啟用 kubelet 報告 NVIDIA GPU 指標的功能。
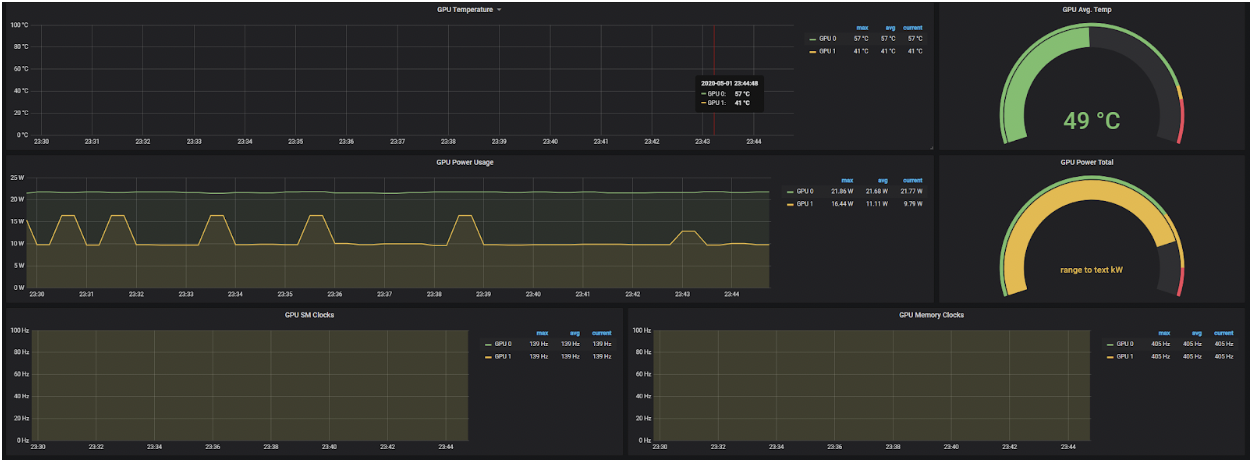
與 Pod Resources API 的畢業配對,這些工具可用於產生 GPU 遙測資料,可用於視覺化儀表板,以下是一個範例
Pod Resources API - 我接下來可以用它做什麼?
一旦引入此介面,許多廠商就開始將其用於廣泛不同的使用案例!列舉一些範例
kuryr-kubernetes CNI 外掛程式與 intel-sriov-device-plugin 結合使用。這允許 CNI 外掛程式知道 kubelet 進行了哪些 SR-IOV 虛擬函式 (VF) 的分配,並使用該資訊正確設定容器網路命名空間,並使用具有適當 NUMA 節點的裝置。我們也期望使用此介面來追蹤已分配和可用的資源,以及有關工作節點 NUMA 拓撲的資訊。
另一個使用案例是 GPU 遙測,其中 GPU 指標可以與 GPU 分配到的容器和 Pod 建立關聯。其中一個範例是 NVIDIA dcgm-exporter,但其他範例也可以在相同的範例中輕鬆建置。
Pod Resources API 是一個簡單的 gRPC 服務,可告知用戶端 kubelet 知道的 Pod。該資訊涉及 kubelet 進行的裝置分配和 CPU 的分配。此資訊分別從 kubelet 的裝置管理員和 CPU 管理員的內部狀態取得。
您可以在下方看到 API 的範例,以及 Go 用戶端如何在幾行程式碼中使用該資訊
service PodResourcesLister {
rpc List(ListPodResourcesRequest) returns (ListPodResourcesResponse) {}
rpc GetAllocatableResources(AllocatableResourcesRequest) returns (AllocatableResourcesResponse) {}
// Kubernetes 1.21
rpc Watch(WatchPodResourcesRequest) returns (stream WatchPodResourcesResponse) {}
}
func main() {
ctx, cancel := context.WithTimeout(context.Background(), connectionTimeout)
defer cancel()
socket := "/var/lib/kubelet/pod-resources/kubelet.sock"
conn, err := grpc.DialContext(ctx, socket, grpc.WithInsecure(), grpc.WithBlock(),
grpc.WithDialer(func(addr string, timeout time.Duration) (net.Conn, error) {
return net.DialTimeout("unix", addr, timeout)
}),
)
if err != nil {
panic(err)
}
client := podresourcesapi.NewPodResourcesListerClient(conn)
resp, err := client.List(ctx, &podresourcesapi.ListPodResourcesRequest{})
if err != nil {
panic(err)
}
net.Printf("%+v\n", resp)
}
最後,請注意,您可以透過監看 kubelet 的 /metrics 端點上稱為 pod_resources_endpoint_requests_total 的新 kubelet 指標,來監看對 Pod Resources 端點發出的請求數量。
裝置監控是否適合生產環境?我可以擴展它嗎?我可以貢獻嗎?
是!此功能在 1.13 中發布,大約 2 年前,已獲得廣泛採用,已被不同的雲端託管服務使用,並且隨著其在 Kubernetes 1.20 中畢業到 G.A,已準備好用於生產環境!
如果您是裝置廠商,您可以立即開始使用它!如果您只想監控叢集中的裝置,請取得最新版本的監控外掛程式!
如果您對該領域充滿熱情,請加入 Kubernetes 社群,協助改進 API 或貢獻裝置監控外掛程式!
致謝
我們感謝為此功能做出貢獻或提供回饋的社群成員,包括 WG-Resource-Management、SIG-Node 和資源管理論壇的成員!