本文已超過一年。較舊的文章可能包含過時的內容。請檢查頁面中的資訊自發布以來是否已變得不正確。
如何在資料密集的 Kubernetes 環境中處理資料重複問題
為什麼要複製資料?
為每個團隊建立應用程式副本及其狀態副本很方便。例如,您可能想要一個單獨的資料庫副本來測試一些重要的結構描述變更,或開發其他破壞性操作,例如大量插入/刪除/更新...
複製資料非常耗時。 這是因為您需要先從來源區塊儲存供應商下載所有資料以進行運算,然後再將其送回儲存供應商。此過程中會使用大量的網路流量和 CPU/RAM。透過將某些昂貴的操作卸載到專用硬體來進行硬體加速始終是效能的巨大提升。它可以將完成操作所需的時間縮短幾個數量級。
Volume Snapshots 來救援
Kubernetes 在 1.12 中引入了 VolumeSnapshots 作為 alpha 版,在 1.17 中作為 beta 版,在 1.20 中作為正式發行版。VolumeSnapshots 使用來自儲存供應商的專用 API 來複製資料磁碟區。
由於資料已經在同一個儲存裝置(裝置陣列)中,因此對於具有本機快照的儲存供應商(大多數內部部署儲存供應商)來說,複製資料通常是中繼資料操作。您只需將新磁碟指向不可變的快照,並僅儲存差異(或讓它執行完整磁碟複製)。作為儲存後端內部的操作,它速度更快,通常不涉及透過網路傳輸流量。公有雲儲存供應商在底層的工作方式略有不同。它們將快照儲存到物件儲存,然後在「複製」磁碟時從物件儲存複製回區塊儲存。從技術上講,雲端供應商端花費了大量的運算和網路資源,但從 Kubernetes 使用者的角度來看,VolumeSnapshots 的運作方式相同,無論是本機還是遠端快照儲存供應商,並且此操作中不涉及運算和網路資源。
聽起來我們有解決方案了,對吧?
實際上,VolumeSnapshots 是命名空間化的,Kubernetes 保護命名空間化的資料不被租戶(命名空間)之間共享。Kubernetes 的這個限制是有意識的設計決策,以便在不同命名空間中運行的 Pod 無法掛載另一個應用程式的 PersistentVolumeClaim (PVC)。
一種解決方法是在一個命名空間中建立具有重複資料的多個磁碟區。但是,您很容易參考到錯誤的副本。
因此,想法是透過命名空間分隔團隊/專案,以避免這種情況,並通常限制對生產命名空間的存取。
解決方案?在外部建立黃金快照
繞過此設計限制的另一種方法是在外部(而不是透過 Kubernetes)建立快照。這也稱為手動預先配置快照。接下來,我將其匯入為多租戶黃金快照,可用於許多命名空間。以下說明將適用於 AWS EBS(彈性區塊儲存)和 GCE PD(永久磁碟)服務。
準備黃金快照的高階計畫
- 在雲端供應商中識別您要使用資料複製的磁碟 (EBS/永久磁碟)
- 建立磁碟快照(在雲端供應商控制台中)
- 取得磁碟快照 ID
為每個團隊複製資料的高階計畫
- 建立命名空間「sandbox01」
- 將磁碟快照 (ID) 作為 VolumeSnapshotContent 匯入到 Kubernetes
- 在命名空間 "sandbox01" 中建立對應到 VolumeSnapshotContent 的 VolumeSnapshot
- 從 VolumeSnapshot 建立 PersistentVolumeClaim
- 使用 PVC 安裝 Deployment 或 StatefulSet
步驟 1:識別磁碟
首先,您需要識別您的黃金來源。在我的案例中,它是「production」命名空間中 PersistentVolumeClaim「postgres-pv-claim」上的 PostgreSQL 資料庫。
kubectl -n <namespace> get pvc <pvc-name> -o jsonpath='{.spec.volumeName}'
輸出將類似於
pvc-3096b3ba-38b6-4fd1-a42f-ec99176ed0d90
步驟 2:準備您的黃金來源
您需要執行此操作一次,或每次想要刷新您的黃金資料時執行。
建立磁碟快照
前往 AWS EC2 或 GCP Compute Engine 控制台,搜尋具有標籤與上次輸出相符的 EBS 磁碟區(在 AWS 上)或永久磁碟(在 GCP 上)。在本例中,我看到:pvc-3096b3ba-38b6-4fd1-a42f-ec99176ed0d9。
按一下「建立快照」並給它一個名稱。您可以在控制台中手動執行、在 AWS CloudShell/Google Cloud Shell 中執行,或在終端機中執行。若要在終端機中建立快照,您必須安裝並設定 AWS CLI 工具 (aws) 或 Google 的 CLI (gcloud)。
以下是在 GCP 上建立快照的命令
gcloud compute disks snapshot <cloud-disk-id> --project=<gcp-project-id> --snapshot-names=<set-new-snapshot-name> --zone=<availability-zone> --storage-location=<region>

GCP 快照建立
GCP 透過其 PVC 名稱識別磁碟,因此它是直接對應。在 AWS 中,您需要先透過具有 PVC 名稱值的 CSIVolumeName AWS 標籤找到磁碟區,該磁碟區將用於快照建立。
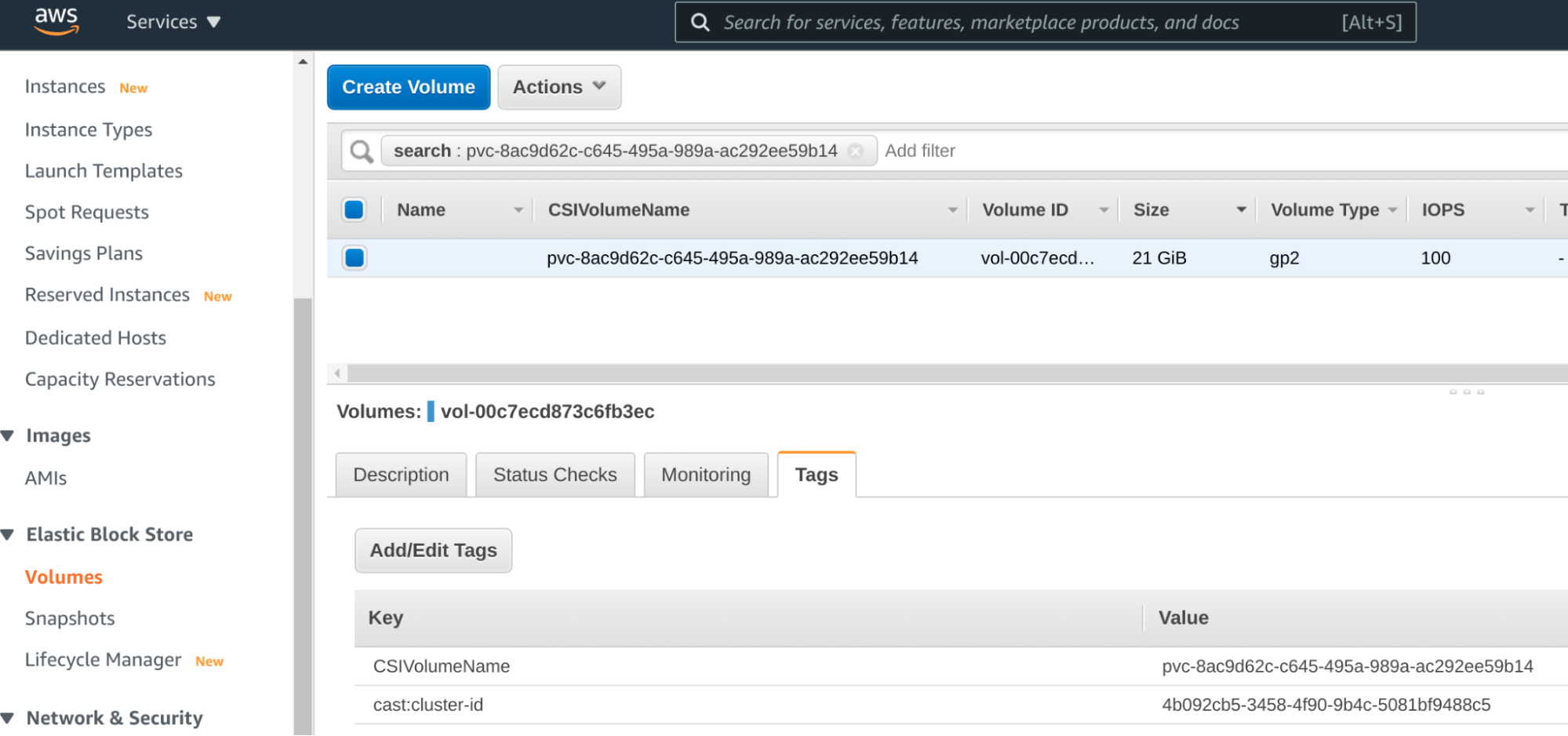
在 AWS 上識別磁碟 ID
標記完成的磁碟區 (volume-id) vol-00c7ecd873c6fb3ec,並在 AWS 控制台中建立 EBS 快照,或使用 aws cli。
aws ec2 create-snapshot --volume-id '<volume-id>' --description '<set-new-snapshot-name>' --tag-specifications 'ResourceType=snapshot'
步驟 3:取得您的磁碟快照 ID
在 AWS 中,上述命令將輸出類似於
"SnapshotId": "snap-09ed24a70bc19bbe4"
如果您使用的是 GCP 雲端,您可以透過查詢給定名稱的快照,從 gcloud 命令取得快照 ID
gcloud compute snapshots --project=<gcp-project-id> describe <new-snapshot-name> | grep id:
您應該會得到類似於
id: 6645363163809389170
步驟 4:為每個團隊建立開發環境
現在我有我的黃金快照,它是不可變的資料。每個團隊都將獲得此資料的副本,團隊成員可以根據自己的需要修改它,前提是將為每個團隊建立新的 EBS/永久磁碟。
下面我將為每個命名空間定義一個 manifest。為了節省時間,您可以使用諸如 sed 或 yq 之類的工具替換命名空間名稱(例如將「sandbox01」→「sandbox42」更改),使用諸如 Kustomize 之類的 Kubernetes 感知範本工具,或在 CI/CD 管道中使用變數替換。
這是一個 manifest 範例
---
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshotContent
metadata:
name: postgresql-orders-db-sandbox01
namespace: sandbox01
spec:
deletionPolicy: Retain
driver: pd.csi.storage.gke.io
source:
snapshotHandle: 'gcp/projects/staging-eu-castai-vt5hy2/global/snapshots/6645363163809389170'
volumeSnapshotRef:
kind: VolumeSnapshot
name: postgresql-orders-db-snap
namespace: sandbox01
---
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshot
metadata:
name: postgresql-orders-db-snap
namespace: sandbox01
spec:
source:
volumeSnapshotContentName: postgresql-orders-db-sandbox01
在 Kubernetes 中,VolumeSnapshotContent (VSC) 物件不是命名空間化的。但是,我需要每個不同的命名空間都有一個單獨的 VSC 才能使用,因此每個 VSC 的 metadata.name 也必須不同。為了使其簡單明瞭,我使用了目標命名空間作為名稱的一部分。
現在是時候用您的 K8s 叢集中安裝的 CSI (容器儲存介面) 驅動程式替換驅動程式欄位。主要的雲端供應商都有支援 VolumeSnapshots 的區塊儲存 CSI 驅動程式,但通常預設情況下未安裝 CSI 驅動程式,請諮詢您的 Kubernetes 供應商。
上面的 manifest 定義了一個在 GCP 上運作的 VSC。在 AWS 上,驅動程式和 SnashotHandle 值可能看起來像
driver: ebs.csi.aws.com
source:
snapshotHandle: "snap-07ff83d328c981c98"
此時,我需要使用 Retain 策略,以便 CSI 驅動程式不會嘗試刪除我手動建立的 EBS 磁碟快照。
對於 GCP,您將必須手動建構此字串 - 新增完整的專案 ID 和快照 ID。對於 AWS,它只是一個普通的快照 ID。
VSC 還需要指定哪個 VolumeSnapshot (VS) 將使用它,因此 VSC 和 VS 相互參考。
現在我可以從上面的 VS 建立 PersistentVolumeClaim。首先設定這個很重要
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: postgres-pv-claim
namespace: sandbox01
spec:
dataSource:
kind: VolumeSnapshot
name: postgresql-orders-db-snap
apiGroup: snapshot.storage.k8s.io
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 21Gi
如果預設 StorageClass 具有 WaitForFirstConsumer 策略,則只有當某些 Pod 綁定該 PVC 時,才會從黃金快照建立實際的雲端磁碟。
現在我將該 PVC 分配給我的 Pod(在我的案例中,它是 Postgresql),就像我對任何其他 PVC 所做的那樣。
kubectl -n <namespace> get volumesnapshotContent,volumesnapshot,pvc,pod
VS 和 VSC 都應該是 READYTOUSE true,PVC 已綁定,並且 Pod(來自 Deployment 或 StatefulSet)正在運行。
為了繼續使用我的黃金快照中的資料,我只需要為下一個命名空間重複此操作,瞧!無需浪費時間和運算資源在複製過程上。