本文已超過一年。較舊的文章可能包含過時的內容。請檢查頁面中的資訊自發布以來是否已變得不正確。
Kubernetes 內部部署 Kubernetes 和 WEDOS PXE 可開機伺服器群
當您擁有兩個資料中心、數千台實體伺服器、虛擬機器以及數十萬個網站的託管服務時,Kubernetes 實際上可以簡化所有這些事物的管理。實務證明,透過使用 Kubernetes,您不僅可以宣告式地描述和管理應用程式,還可以宣告式地描述和管理基礎架構本身。我在捷克最大的託管服務供應商 WEDOS Internet a.s 工作,今天我將向您展示我的兩個專案 — Kubernetes-in-Kubernetes 和 Kubefarm。
借助它們的幫助,您只需幾個命令即可使用 Helm 在另一個 Kubernetes 內部部署功能完善的 Kubernetes 叢集。如何以及為什麼?
讓我向您介紹我們的基礎架構如何運作。我們所有的實體伺服器可以分為兩組:控制平面和 計算 節點。控制平面節點通常是手動設定的,已安裝穩定的作業系統,旨在運行所有叢集服務,包括 Kubernetes 控制平面。這些節點的主要任務是確保叢集本身的順暢運作。計算節點預設未安裝任何作業系統,而是直接從控制平面節點透過網路啟動作業系統映像。它們的工作是執行工作負載。

節點下載映像後,它們可以繼續工作,而無需保持與 PXE 伺服器的連線。也就是說,PXE 伺服器僅保留 rootfs 映像,不保留任何其他複雜邏輯。在我們的節點啟動後,我們可以安全地重新啟動 PXE 伺服器,它們不會發生任何重大問題。

啟動後,我們的節點做的第一件事是加入現有的 Kubernetes 叢集,即執行 kubeadm join 命令,以便 kube-scheduler 可以在它們上排程一些 Pod 並隨後啟動各種工作負載。從一開始,我們就使用了將節點加入到用於控制平面節點的同一個叢集的方案。

這個方案穩定運作了兩年多。然而,後來我們決定向其中新增容器化的 Kubernetes。現在我們可以非常輕鬆地在我們的控制平面節點上產生新的 Kubernetes 叢集,這些節點現在是特殊的管理員叢集的成員。現在,計算節點可以直接加入到它們自己的叢集 — 具體取決於組態。

Kubefarm
這個專案的目標是讓任何人只需幾個命令即可使用 Helm 部署這樣的基礎架構,並最終獲得大致相同的結果。
此時,我們放棄了單一叢集的想法。因為事實證明,在同一個叢集中管理多個開發團隊的工作不是很方便。事實是,Kubernetes 從未設計為多租戶解決方案,目前它沒有提供足夠的專案之間隔離手段。因此,為每個團隊運行單獨的叢集證明是一個好主意。但是,叢集不應過多,以便於管理。也不宜過少,以確保開發團隊之間有足夠的獨立性。
在進行此變更後,我們叢集的可擴展性明顯提高。每個節點數量擁有的叢集越多,故障域就越小,它們的工作就越穩定。作為額外的好處,我們獲得了一個完全宣告式描述的基礎架構。因此,現在您可以像在 Kubernetes 中部署任何其他應用程式一樣部署新的 Kubernetes 叢集。
它使用 Kubernetes-in-Kubernetes 作為基礎,LTSP 作為 PXE 伺服器(節點從該伺服器啟動),並使用 dnsmasq-controller 自動化 DHCP 伺服器組態
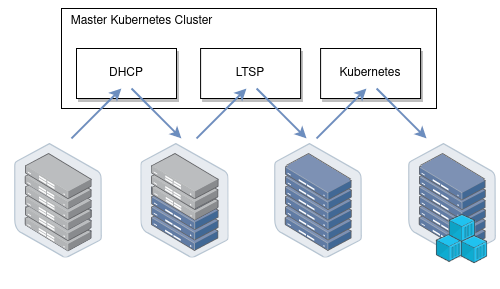
運作方式
現在讓我們看看它的運作方式。一般來說,如果您從應用程式的角度來看 Kubernetes,您會注意到它遵循 The Twelve-Factor App 的所有原則,並且實際上編寫得非常好。因此,這意味著在另一個 Kubernetes 中將 Kubernetes 作為應用程式運行應該不是什麼大問題。
在 Kubernetes 中運行 Kubernetes
現在讓我們看一下 Kubernetes-in-Kubernetes 專案,它為在 Kubernetes 中運行 Kubernetes 提供了現成的 Helm chart。
以下是您可以在 values 檔案中傳遞給 Helm 的參數

除了 persistence(叢集的儲存參數)之外,這裡還描述了 Kubernetes 控制平面組件:即:etcd 叢集、apiserver、controller-manager 和 scheduler。這些幾乎是標準的 Kubernetes 組件。有一個輕鬆的說法是「Kubernetes 只是五個二進位檔案」。因此,這裡就是這些二進位檔案的組態所在。
如果您曾經嘗試使用 kubeadm 引導叢集,那麼此組態會讓您想起它的組態。但除了 Kubernetes 實體之外,您還有一個管理員容器。事實上,它是一個容器,內部包含兩個二進位檔案:kubectl 和 kubeadm。它們用於為上述組件產生 kubeconfig,並執行叢集的初始組態。此外,在緊急情況下,您可以隨時 exec 進入其中以檢查和管理您的叢集。
在發布 部署完成 後,您可以看到 Pod 的清單:admin-container、兩個副本中的 apiserver、controller-manager、etcd-cluster、scheduller 和初始化叢集的初始 Job。最後,您會得到一個命令,讓您可以進入管理員容器的 shell,您可以使用它來查看內部發生的情況

此外,讓我們看一下憑證。如果您曾經安裝過 Kubernetes,那麼您就會知道它有一個可怕的目錄 /etc/kubernetes/pki,其中包含一堆憑證。在 Kubernetes-in-Kubernetes 的情況下,您可以使用 cert-manager 完全自動化地管理它們。因此,只需在安裝期間將所有憑證參數傳遞給 Helm,所有憑證都將自動為您的叢集產生。

查看其中一個憑證,例如 apiserver,您可以看到它有一個 DNS 名稱和 IP 位址的清單。如果您想讓此叢集在外部可存取,只需在 values 檔案中描述其他 DNS 名稱並更新發布。這將更新憑證資源,而 cert-manager 將重新產生憑證。您不再需要考慮這個問題。如果 kubeadm 憑證至少每年需要續訂一次,那麼 cert-manager 將會處理並自動續訂它們。

現在讓我們登入管理員容器並查看叢集和節點。當然,目前還沒有節點,因為目前您只部署了 Kubernetes 的空白控制平面。但在 kube-system 命名空間中,您可以看到一些 coredns Pod 正在等待排程,並且 configmap 已經出現。也就是說,您可以得出結論,叢集正在運作

這是 部署的叢集圖表。您可以看到所有 Kubernetes 組件的服務:apiserver、controller-manager、etcd-cluster 和 scheduler。以及它們將流量轉發到的右側 Pod。
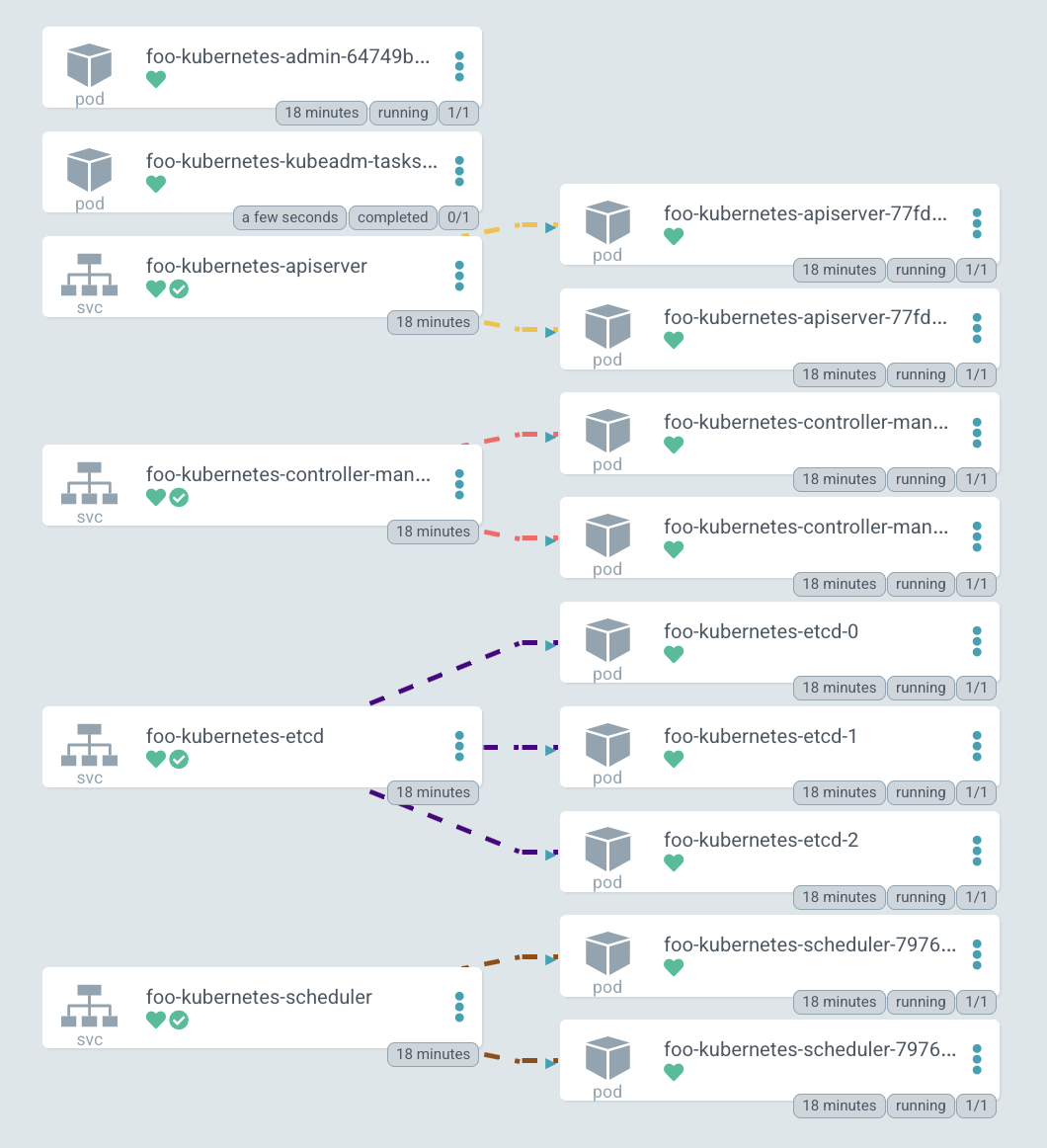
順便說一句,該圖表是在 ArgoCD 中繪製的 — 我們用來管理叢集的 GitOps 工具,而酷炫的圖表是其功能之一。
協調實體伺服器
好的,現在您可以看到我們的 Kubernetes 控制平面是如何部署的,但是工作節點呢,我們如何新增它們?正如我已經說過的,我們所有的伺服器都是裸機伺服器。我們不使用虛擬化來運行 Kubernetes,而是我們自己協調所有實體伺服器。
此外,我們非常積極地使用 Linux 網路啟動功能。而且,這正是啟動,而不是安裝的某種自動化。當節點啟動時,它們只是為它們運行現成的系統映像。也就是說,要更新任何節點,我們只需要重新啟動它 — 它就會下載新的映像。這非常容易、簡單且方便。
為此,創建了 Kubefarm 專案,讓您可以自動執行此操作。最常用的範例可以在 examples 目錄中找到。其中最標準的範例名為 generic。讓我們看一下 values.yaml
在這裡,您可以指定傳遞到上游 Kubernetes-in-Kubernetes chart 中的參數。為了讓您的控制平面可以從外部存取,在這裡指定 IP 位址就足夠了,但如果您願意,您可以在這裡指定一些 DNS 名稱。
在 PXE 伺服器組態中,您可以指定時區。您還可以新增 SSH 金鑰以在無需密碼的情況下登入(但您也可以指定密碼),以及在系統啟動期間應套用的核心模組和參數。
接下來是 nodePools 組態,即節點本身。如果您曾經使用過 gke 的 terraform 模組,那麼此邏輯會讓您想起它。在這裡,您可以靜態地描述具有一組參數的所有節點
名稱 (主機名稱);
MAC 位址 — 我們的節點有兩張網卡,並且每張網卡都可以從此處指定的任何 MAC 位址啟動。
IP 位址,DHCP 伺服器應將其頒發給此節點。
在此範例中,您有兩個池:第一個池有五個節點,第二個池只有一個,第二個池也分配了兩個標籤。標籤是用於描述特定節點組態的方式。例如,您可以為某些池新增特定的 DHCP 選項、用於 PXE 伺服器啟動的選項(例如,此處啟用了偵錯選項)以及一組 kubernetesLabels 和 kubernetesTaints 選項。這意味著什麼?
例如,在此組態中,您有一個節點的第二個 nodePool。該池分配了 debug 和 foo 標籤。現在查看 kubernetesLabels 中 foo 標籤的選項。這表示 m1c43 節點將使用分配的這兩個標籤和污點啟動。一切似乎都很簡單。現在讓我們在實務中 嘗試 一下。
示範
前往 examples 並將先前部署的 chart 更新為 Kubefarm。只需使用 generic 參數並查看 Pod。您可以看到新增了一個 PXE 伺服器和一個更多 Job。此 Job 基本上會前往已部署的 Kubernetes 叢集並建立新的令牌。現在它將每 12 小時重複運行以產生新令牌,以便節點可以連線到您的叢集。

在 圖形表示 中,它看起來大致相同,但現在 apiserver 開始在外部公開。
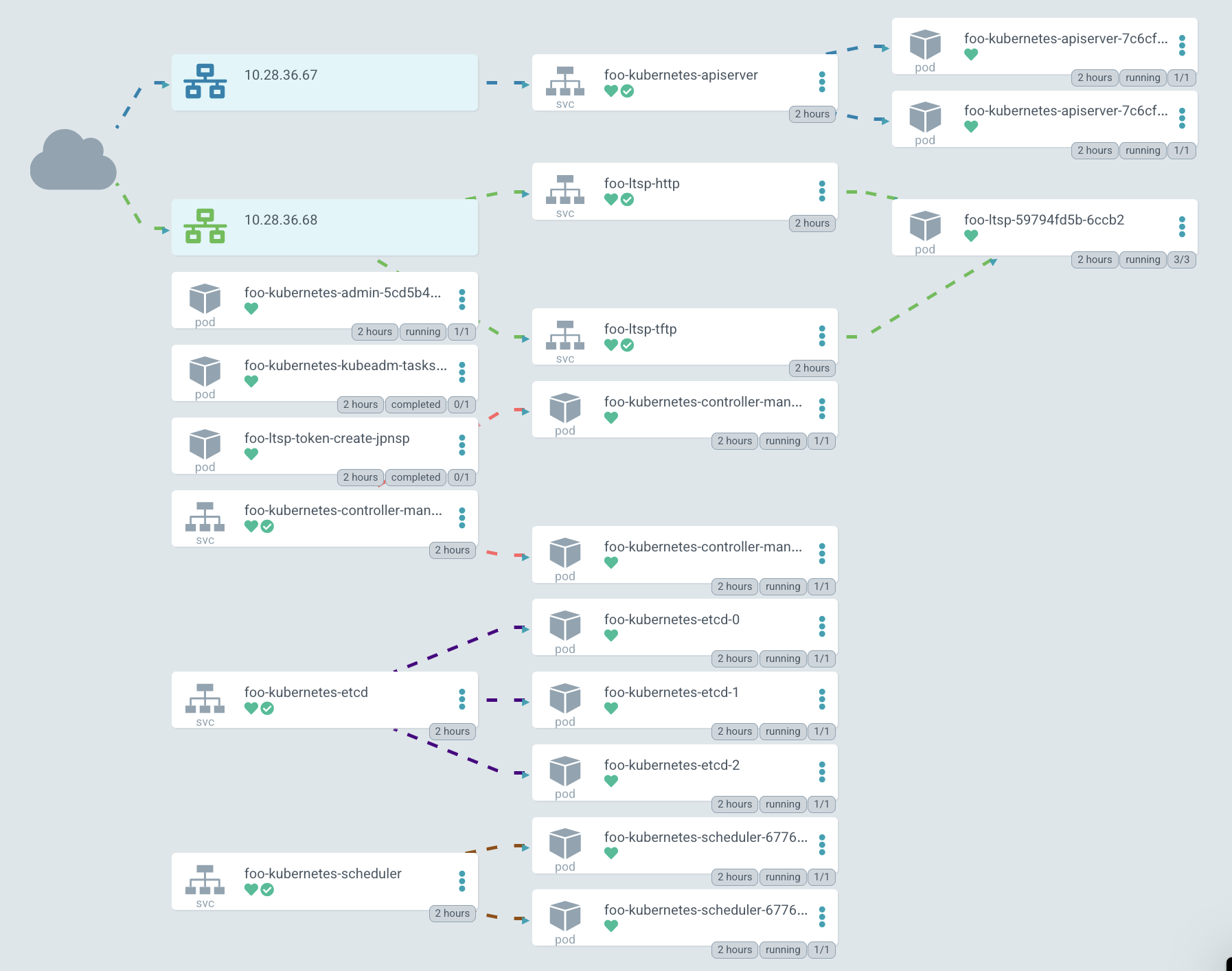
在圖表中,IP 以綠色突出顯示,PXE 伺服器可以透過它訪問。目前,Kubernetes 預設不允許為 TCP 和 UDP 協定建立單一 LoadBalancer 服務,因此您必須建立兩個具有相同 IP 位址的不同服務。一個用於 TFTP,第二個用於 HTTP,系統映像透過 HTTP 下載。
但這個簡單的範例並不總是足夠,有時您可能需要在啟動時修改邏輯。例如,這裡有一個目錄 advanced_network,其中有一個帶有簡單 shell 腳本的 values 檔案。讓我們稱之為 network.sh
所有此腳本所做的事情都是在啟動時取得環境變數,並根據它們產生網路組態。它建立一個目錄並將 netplan 組態放入其中。例如,此處建立了一個綁定介面。基本上,此腳本可以包含您需要的一切。它可以包含網路組態或產生系統服務、新增一些 hook 或描述任何其他邏輯。任何可以在 bash 或 shell 語言中描述的內容都可以在這裡運作,並且它將在啟動時執行。
讓我們看看如何 部署 它。讓我們將 generic values 檔案作為第一個參數傳遞,並將另一個 values 檔案作為第二個參數傳遞。這是標準的 Helm 功能。透過這種方式,您也可以傳遞密碼,但在這種情況下,組態僅由第二個檔案擴充

讓我們查看 netboot 伺服器的 configmap foo-kubernetes-ltsp,並確保 network.sh 腳本確實存在。這些命令用於在啟動時組態網路

這裡 您可以看到它的運作原理。機箱介面(我們使用 HPE Moonshots 1500)具有節點,您可以輸入 show node list 命令以取得所有節點的清單。現在您可以看到啟動過程。

您也可以透過 show node macaddr all 命令取得它們的 MAC 位址。我們有一個聰明的運算子,可以自動從機箱收集 MAC 位址並將它們傳遞給 DHCP 伺服器。實際上,它只是為在同一個管理員 Kubernetes 叢集中運行的 dnsmasq-controller 建立自訂組態資源。此外,透過此介面,您可以控制節點本身,例如開啟和關閉它們。
如果您沒有機會透過 iLO 進入機箱並收集節點的 MAC 位址清單,您可以考慮使用 catchall 叢集 模式。純粹來說,它只是一個具有動態 DHCP 池的叢集。因此,未在其他叢集的組態中描述的所有節點都會自動加入到此叢集。

例如,您可以看到一個特殊的叢集,其中包含一些節點。它們已加入到具有基於其 MAC 位址自動產生的名稱的叢集。從這一點開始,您可以連線到它們並查看那裡發生的情況。在這裡,您可以以某種方式準備它們,例如,設定檔案系統,然後將它們重新加入到另一個叢集。
現在讓我們嘗試連線到節點終端機並查看它是如何啟動的。在 BIOS 之後,網卡已組態,此處它從特定 MAC 位址向 DHCP 伺服器發送請求,DHCP 伺服器將其重新導向到特定的 PXE 伺服器。稍後,核心和 initrd 映像將使用標準 HTTP 協定從伺服器下載

載入核心後,節點會下載 rootfs 映像並將控制權轉移到 systemd。然後啟動照常進行,之後節點加入 Kubernetes

如果您查看 fstab,您只能看到兩個條目:/var/lib/docker 和 /var/lib/kubelet,它們以 tmpfs 的形式掛載(實際上是從 RAM 掛載)。同時,根分割區以 overlayfs 的形式掛載,因此您在此系統上所做的所有變更都將在下次重新啟動時遺失。
查看節點上的塊設備,您可以看到一些 nvme 磁碟,但它尚未掛載到任何地方。還有一個迴圈設備 — 這正是從伺服器下載的 rootfs 映像。目前它位於 RAM 中,佔用 653 MB 並以 loop 選項掛載。
如果您查看 /etc/ltsp,您會找到在啟動時執行的 network.sh 檔案。從容器中,您可以看到正在運行的 kube-proxy 和 pause 容器。

詳細資訊
網路啟動映像
但是主映像從哪裡來呢?這裡有一個小技巧。節點的映像是透過 Dockerfile 與伺服器一起建構的。Docker 多階段建構 功能讓您可以輕鬆地在映像建構階段新增任何套件和核心模組。它看起來像這樣
這裡發生了什麼事?首先,我們採用常規的 Ubuntu 20.04 並安裝我們需要的所有套件。首先,我們安裝 kernel、lvm、systemd、ssh。一般來說,您希望在最終節點上看到的所有內容都應在此處描述。在這裡,我們還安裝了 docker 以及 kubelet 和 kubeadm,它們用於將節點加入到叢集中。
然後我們執行額外的組態。在最後階段,我們只需安裝 tftp 和 nginx(為我們的用戶端提供映像)、grub (啟動程式)。然後將先前階段的根目錄複製到最終映像中,並從中產生壓縮映像。也就是說,實際上,我們獲得了一個 docker 映像,其中同時包含伺服器和節點的啟動映像。同時,可以透過變更 Dockerfile 輕鬆更新它。
Webhook 和 API 聚合層
我想特別關注 webhook 和聚合層的問題。一般來說,webhook 是一種 Kubernetes 功能,可讓您回應任何資源的建立或修改。因此,您可以新增一個處理程序,以便在應用資源時,Kubernetes 必須向某個 Pod 發送請求,並檢查此資源的組態是否正確,或對其進行其他變更。
但重點是,為了讓 webhook 運作,apiserver 必須具有對其運行的叢集的直接存取權。如果它在單獨的叢集中啟動,例如我們的案例,甚至與任何叢集分開啟動,那麼 Konnectivity 服務可以幫助我們。Konnectivity 是可選但官方支援的 Kubernetes 組件之一。
讓我們以四個節點的叢集為例,每個節點都在運行 kubelet,並且我們在外部運行其他 Kubernetes 組件:kube-apiserver、kube-scheduler 和 kube-controller-manager。預設情況下,所有這些組件都直接與 apiserver 互動 — 這是 Kubernetes 邏輯中最著名的部分。但實際上,也存在反向連線。例如,當您想要查看日誌或運行 kubectl exec command 時,API 伺服器會獨立地建立與特定 kubelet 的連線

但問題是,如果我們有一個 webhook,那麼它通常作為叢集中具有服務的標準 Pod 運行。當 apiserver 嘗試訪問它時,它將失敗,因為它將嘗試訪問名為 webhook.namespace.svc 的叢集內服務,但它實際上在叢集外部運行

而 Konnectivity 可以幫助我們解決這個問題。Konnectivity 是一個專門為 Kubernetes 開發的棘手代理伺服器。它可以作為伺服器部署在 apiserver 旁邊。Konnectivity-agent 以多個副本的形式直接部署在您要訪問的叢集中。代理建立與伺服器的連線並設定穩定的通道,使 apiserver 能夠存取叢集中的所有 webhook 和所有 kubelet。因此,現在與叢集的所有通訊都將透過 Konnectivity-server 進行

我們的計劃
當然,我們不會停留在這個階段。對專案感興趣的人經常寫信給我。如果感興趣的人數足夠多,我希望將 Kubernetes-in-Kubernetes 專案移至 Kubernetes SIGs 下,以官方 Kubernetes Helm chart 的形式呈現它。也許,透過使這個專案獨立,我們將聚集更大的社群。
我也在考慮將其與 Machine Controller Manager 集成,這將允許建立工作節點,不僅適用於實體伺服器,也適用於例如使用 kubevirt 建立虛擬機器並在同一個 Kubernetes 叢集中運行它們。順便說一句,它還允許在雲端產生虛擬機器,並在本地部署控制平面。
我也在考慮與 Cluster-API 集成的選項,以便您可以直接透過 Kubernetes 環境建立實體 Kubefarm 叢集。但目前我還不太確定這個想法。如果您對此事有任何想法,我很樂意傾聽。