本文已超過一年。較舊的文章可能包含過時的內容。請檢查頁面中的資訊自發布以來是否已變得不正確。
透過 OpenTelemetry 提升 Kubernetes 容器執行階段可觀察性
當談到雲原生領域的可觀察性時,那麼可能每個人都會在談話中提到 OpenTelemetry (OTEL)。這很棒,因為社群需要標準來依賴,以便將所有叢集組件朝相同的方向開發。 OpenTelemetry 使我們能夠將日誌、指標、追蹤和其他上下文資訊(稱為 baggage)組合到單一資源中。叢集管理員或軟體工程師可以使用此資源來取得關於叢集在定義時間段內發生情況的視窗。但是 Kubernetes 本身如何利用這種技術堆疊呢?
Kubernetes 由多個組件組成,其中一些是獨立的,另一些則堆疊在一起。從容器執行階段的角度來看架構,那麼從上到下有:
- kube-apiserver:驗證和配置 API 物件的資料
- kubelet:在每個節點上運行的代理程式
- CRI runtime:容器執行階段介面 (CRI) 相容的容器執行階段,例如 CRI-O 或 containerd
- OCI runtime:較低層級的 開放容器倡議 (OCI) 執行階段,例如 runc 或 crun
- Linux kernel 或 Microsoft Windows:底層作業系統
這表示如果我們在 Kubernetes 中運行容器時遇到問題,那麼我們將開始查看其中一個組件。找出問題的根本原因是我們在當今叢集設定中日益增加的架構複雜性中所面臨的最耗時的操作之一。即使我們知道似乎導致問題的組件,我們仍然必須考慮其他組件,以維持正在發生的事件的心理時間軸。我們如何實現這一點?嗯,大多數人可能會堅持抓取日誌、過濾它們並跨組件邊界將它們組裝在一起。我們也有指標,對吧?沒錯,但是將指標值與純日誌相關聯,使得追蹤正在發生的事情變得更加困難。有些指標也不是為除錯目的而設計的。它們是根據叢集的最終使用者角度定義的,用於連結可用的警報,而不是用於開發人員除錯叢集設定。
OpenTelemetry 來救援:該專案旨在將 追蹤、指標 和 日誌 等訊號組合在一起,以維持叢集狀態的正確視窗。
Kubernetes 中 OpenTelemetry 追蹤的目前狀態是什麼?從 API 伺服器的角度來看,自 Kubernetes v1.22 以來,我們對追蹤具有 alpha 支援,這將在即將發布的版本之一中升級為 beta 版。不幸的是,beta 版升級錯過了 v1.26 Kubernetes 版本。設計提案可以在 API Server Tracing Kubernetes 增強提案 (KEP) 中找到,其中提供了更多相關資訊。
kubelet 追蹤部分在 另一個 KEP 中追蹤,該 KEP 在 Kubernetes v1.25 中以 alpha 狀態實作。在撰寫本文時,尚未計劃 beta 版升級,但在 v1.27 版本週期中可能會推出更多內容。除了這兩個 KEP 之外,還有其他附帶工作正在進行中,例如 klog 正在考慮 OTEL 支援,這將透過將日誌訊息連結到現有追蹤來提升可觀察性。在 SIG Instrumentation 和 SIG Node 內,我們也在討論 如何將 kubelet 追蹤連結在一起,因為目前它們專注於 kubelet 和 CRI 容器執行階段之間的 gRPC 呼叫。
CRI-O 自 v1.23.0 以來 就具有 OpenTelemetry 追蹤支援,並且正在不斷改進它們,例如透過 將日誌附加到追蹤 或擴展 span 到應用程式的邏輯部分。這有助於追蹤使用者獲得與解析日誌相同的資訊,但具有增強的範圍界定和篩選到其他 OTEL 訊號的功能。 CRI-O 維護者也在開發 conmon 的容器監控替代品,稱為 conmon-rs,它完全用 Rust 語言編寫。擁有 Rust 實作的一個好處是能夠添加 OpenTelemetry 支援等功能,因為這些功能的 crates(程式庫)已經存在。這允許與 CRI-O 緊密整合,並讓消費者看到來自其容器的最低層級追蹤資料。
containerd 人員自 v1.6.0 以來新增了追蹤支援,可以透過 使用外掛程式 來使用。較低層級的 OCI 執行階段(例如 runc 或 crun)完全不支援 OTEL,並且似乎沒有相關計劃。我們始終必須考慮到,收集追蹤以及將它們匯出到資料接收器時,都存在效能開銷。我仍然認為值得評估擴展的遙測收集在 OCI 執行階段中的外觀。讓我們看看 Rust OCI 執行階段 youki 未來是否會考慮類似的事情。
我將向您展示如何試用它。對於我的演示,我將堅持使用具有 runc、conmon-rs、CRI-O 和 kubelet 的單一本地節點堆疊。為了在 kubelet 中啟用追蹤,我需要套用以下 KubeletConfiguration
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
featureGates:
KubeletTracing: true
tracing:
samplingRatePerMillion: 1000000
samplingRatePerMillion 等於一百萬將在內部轉換為取樣所有內容。類似的配置必須應用於 CRI-O;我可以啟動 crio 二進制文件,並帶有 --enable-tracing 和 --tracing-sampling-rate-per-million 1000000,或者我們使用像這樣的 drop-in 配置
cat /etc/crio/crio.conf.d/99-tracing.conf
[crio.tracing]
enable_tracing = true
tracing_sampling_rate_per_million = 1000000
要配置 CRI-O 以使用 conmon-rs,您至少需要最新的 CRI-O v1.25.x 和 conmon-rs v0.4.0。然後可以使用像這樣的配置 drop-in 來使 CRI-O 使用 conmon-rs
cat /etc/crio/crio.conf.d/99-runtimes.conf
[crio.runtime]
default_runtime = "runc"
[crio.runtime.runtimes.runc]
runtime_type = "pod"
monitor_path = "/path/to/conmonrs" # or will be looked up in $PATH
就是這樣,預設配置將指向 localhost:4317 的 OpenTelemetry 收集器 gRPC 端點,該端點也必須已啟動並運行。有多種運行 OTLP 的方法,如 文件中所述,但也可以 kubectl proxy 到 Kubernetes 中運行的現有實例中。
如果一切都設定好了,那麼收集器應該記錄有傳入的追蹤
ScopeSpans #0
ScopeSpans SchemaURL:
InstrumentationScope go.opentelemetry.io/otel/sdk/tracer
Span #0
Trace ID : 71896e69f7d337730dfedb6356e74f01
Parent ID : a2a7714534c017e6
ID : 1d27dbaf38b9da8b
Name : github.com/cri-o/cri-o/server.(*Server).filterSandboxList
Kind : SPAN_KIND_INTERNAL
Start time : 2022-11-15 09:50:20.060325562 +0000 UTC
End time : 2022-11-15 09:50:20.060326291 +0000 UTC
Status code : STATUS_CODE_UNSET
Status message :
Span #1
Trace ID : 71896e69f7d337730dfedb6356e74f01
Parent ID : a837a005d4389579
ID : a2a7714534c017e6
Name : github.com/cri-o/cri-o/server.(*Server).ListPodSandbox
Kind : SPAN_KIND_INTERNAL
Start time : 2022-11-15 09:50:20.060321973 +0000 UTC
End time : 2022-11-15 09:50:20.060330602 +0000 UTC
Status code : STATUS_CODE_UNSET
Status message :
Span #2
Trace ID : fae6742709d51a9b6606b6cb9f381b96
Parent ID : 3755d12b32610516
ID : 0492afd26519b4b0
Name : github.com/cri-o/cri-o/server.(*Server).filterContainerList
Kind : SPAN_KIND_INTERNAL
Start time : 2022-11-15 09:50:20.0607746 +0000 UTC
End time : 2022-11-15 09:50:20.060795505 +0000 UTC
Status code : STATUS_CODE_UNSET
Status message :
Events:
SpanEvent #0
-> Name: log
-> Timestamp: 2022-11-15 09:50:20.060778668 +0000 UTC
-> DroppedAttributesCount: 0
-> Attributes::
-> id: Str(adf791e5-2eb8-4425-b092-f217923fef93)
-> log.message: Str(No filters were applied, returning full container list)
-> log.severity: Str(DEBUG)
-> name: Str(/runtime.v1.RuntimeService/ListContainers)
我可以看到 span 具有追蹤 ID,並且通常附加了父項。諸如日誌之類的事件也是輸出的一部分。在上面的案例中,kubelet 正在定期觸發到 CRI-O 的 ListPodSandbox RPC,這是由 Pod Lifecycle Event Generator (PLEG) 引起的。顯示這些追蹤可以透過例如 Jaeger 完成。當在本地運行追蹤堆疊時,Jaeger 實例預設應在 http://localhost:16686 上公開。
ListPodSandbox 請求在 Jaeger UI 中直接可見
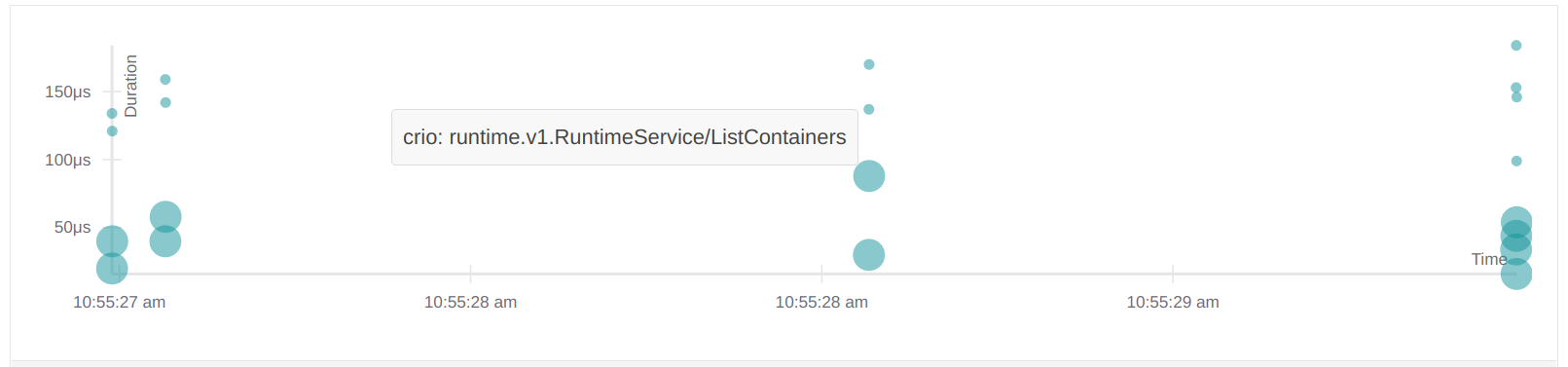
這不是太令人興奮,所以我將直接透過 kubectl 運行工作負載
kubectl run -it --rm --restart=Never --image=alpine alpine -- echo hi
hi
pod "alpine" deleted
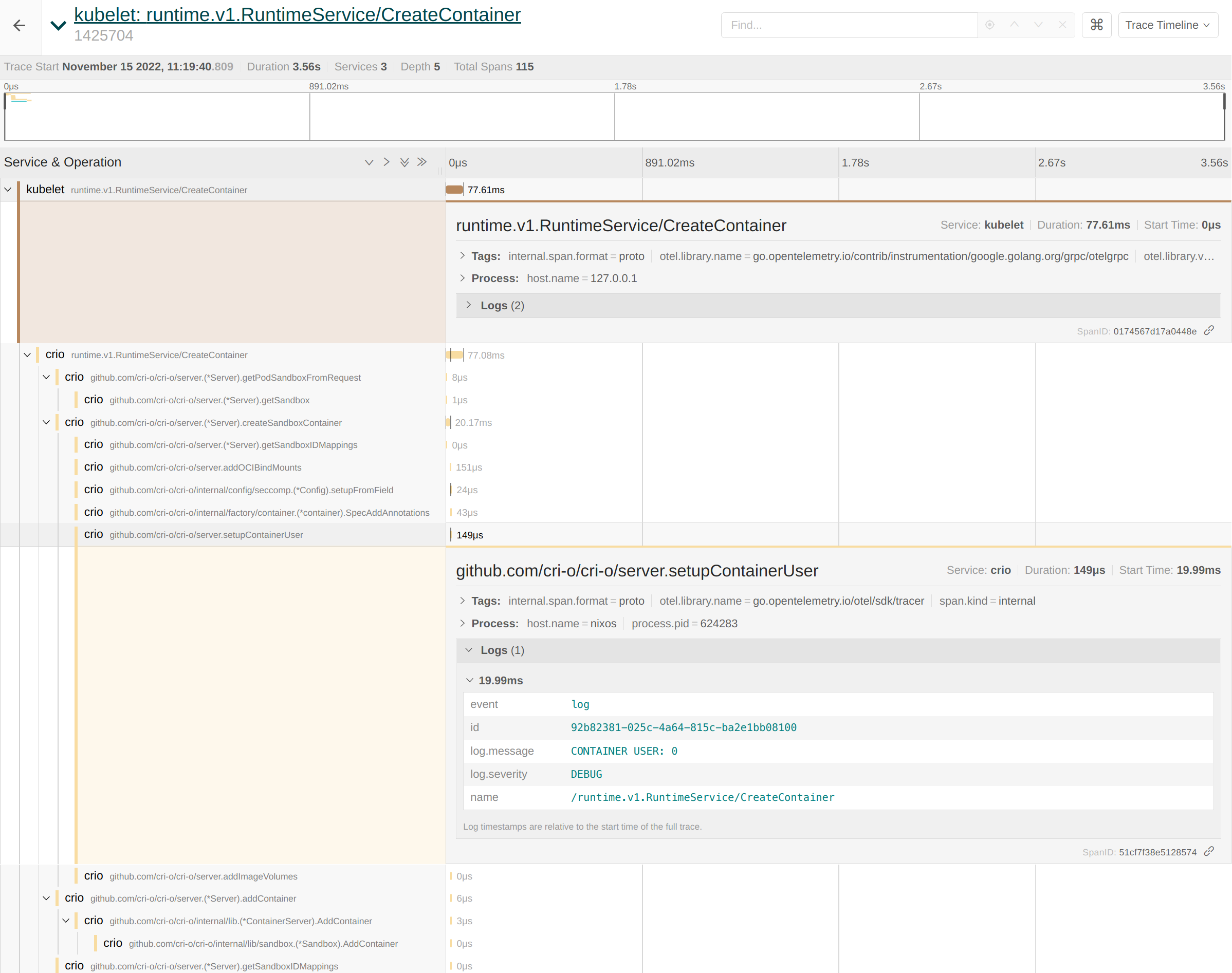
現在查看 Jaeger,我們可以看見針對 conmonrs、crio 以及 kubelet 的 RunPodSandbox 和 CreateContainer CRI RPC 的追蹤

kubelet 和 CRI-O span 相互連接,以使調查更容易。如果我們現在仔細查看 span,那麼我們可以看到 CRI-O 的日誌已正確地添加到相應的功能中。例如,我們可以從追蹤中提取容器使用者,如下所示
conmon-rs 的較低層級 span 也是此追蹤的一部分。例如,conmon-rs 維護一個內部 read_loop,用於處理容器和最終使用者之間的 IO。讀取和寫入位元組的日誌是 span 的一部分。這也適用於 wait_for_exit_code span,它告訴我們容器以程式碼 0 成功退出
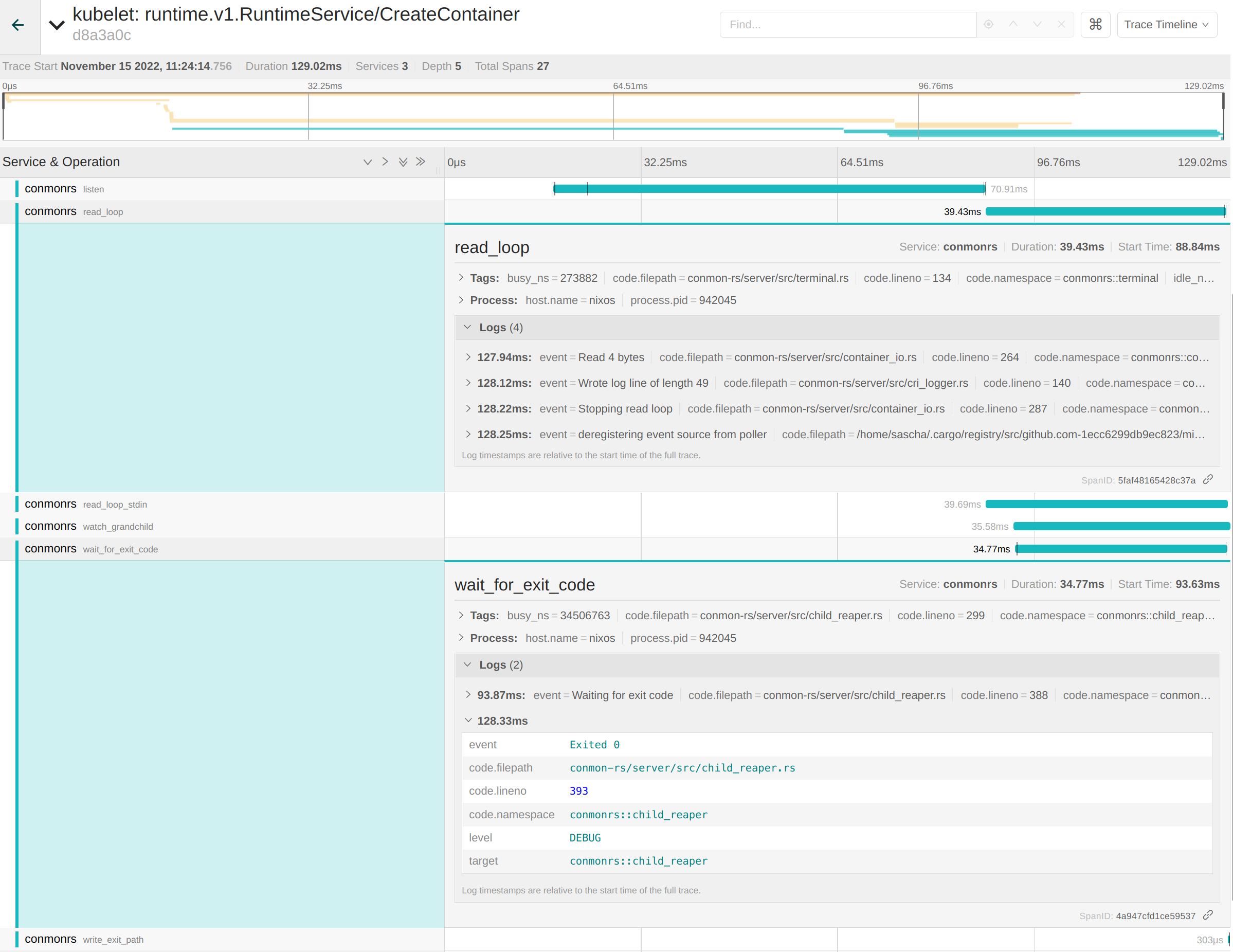
並排擁有所有這些資訊以及 Jaeger 的篩選功能,使整個堆疊成為除錯容器問題的絕佳解決方案!提到“整個堆疊”也顯示了整體方法的最大缺點:與解析日誌相比,它在叢集設定之上增加了一個明顯的開銷。使用者必須維護像 Elasticsearch 這樣的接收器來持久保存資料、公開 Jaeger UI,並可能考慮效能上的缺點。無論如何,它仍然是提高 Kubernetes 可觀察性方面的最佳方法之一。
感謝您閱讀這篇部落格文章,我非常肯定我們正在展望 Kubernetes 中 OpenTelemetry 支援的光明未來,以使故障排除更簡單。